
こんにちは。カルークです。
過去の記事で、エクセルを使ってピボットテーブルの操作方法についてまとめました。
今回はPythonを使ってピボットテーブルを使う方法について書きます。
Pythonでピボットテーブルを使う
pandasのパッケージインストール
Pythonでピボットテーブルを使うには、Pandasと呼ばれるパッケージをインストールする必要があります。
まずは作業用の仮想環境に入っておきます。

続いて、Pandasとnumpyをインストールします。
(data_tech_log) C:\Users\caluke>conda install pandasインストール後、念の為ちゃんと入ったかどうかを確認します。そのままAnaconda Prompt上でpythonを起動し、パッケージのインポートをしてエラーがでなければ成功です。
(data_tech_log) C:\Users\caluke>python
Python 3.6.10 |Anaconda, Inc.| (default, Mar 23 2020, 17:58:33) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas # これでエラーがでなければOK
>>> import numpy # これでエラーがでなければOK準備が整いました。
データの読み込み
作業はjupyter notebookで行います。
下記のような家計簿のデータがあったとします。csvで.ipynbと同じディレクトリに置いておきます。(手元で実行する場合は、以下をコピペしてcsvとして保存します)
| 計算対象 | 日 | 内容 | ジャンル | 金額(円) |
| 1 | 2020/4/1 | 食材購入 | 食費 | ¥2,500 |
| 1 | 2020/4/1 | ゲームソフト | 娯楽 | ¥5,500 |
| 1 | 2020/4/1 | コンビニ(ランチ) | 食費 | ¥700 |
| 1 | 2020/4/1 | コンビニ(ジュース) | 食費 | ¥150 |
| 1 | 2020/4/1 | 飲み物 | 食費 | ¥130 |
| 1 | 2020/4/1 | 飲み物 | 食費 | ¥130 |
| 1 | 2020/4/2 | カフェ | 食費 | ¥400 |
| 1 | 2020/4/2 | スマホケース | 娯楽 | ¥800 |
| 1 | 2020/4/2 | 食材購入 | 食費 | ¥1,400 |
| 1 | 2020/4/2 | 飲み物 | 食費 | ¥200 |
| 1 | 2020/4/2 | 書籍 | 娯楽 | ¥2,500 |
| 0 | 2020/4/3 | 経費立替 | 仕事 | ¥5,000 |
| 1 | 2020/4/3 | カフェ | 食費 | ¥300 |
| 1 | 2020/4/3 | ランチ | 食費 | ¥500 |
| 1 | 2020/4/4 | 食材購入 | 食費 | ¥3,000 |
| 1 | 2020/4/4 | ラーメン | 食費 | ¥850 |
| 1 | 2020/4/5 | 電車賃 | 交通費 | ¥500 |
| 1 | 2020/4/5 | カフェ | 食費 | ¥450 |
| 1 | 2020/4/5 | ドラッグストア | 日用品 | ¥3,000 |
| 1 | 2020/4/5 | ランチ | 食費 | ¥900 |
| 1 | 2020/4/5 | パソコンソフト | 娯楽 | ¥2,800 |
| 0 | 2020/4/5 | 飲み会立替 | 娯楽 | ¥9,000 |
| 1 | 2020/4/5 | タクシー | 交通費 | ¥4,500 |
| 1 | 2020/4/6 | 食材購入 | 食費 | ¥1,500 |
| 1 | 2020/4/6 | 夕飯 | 食費 | ¥1,200 |
| 1 | 2020/4/6 | 洋服 | 衣料品 | ¥4,000 |
| 1 | 2020/4/7 | 食材購入 | 食費 | ¥2,000 |
| 1 | 2020/4/7 | バス | 交通費 | ¥230 |
| 1 | 2020/4/7 | カフェ | 食費 | ¥420 |
| 1 | 2020/4/7 | 飲み物 | 食費 | ¥120 |
numpy, pandasのパッケージをインポートします。
import pandas as pd
import numpy as npcsvを読み込みます。
df = pd.read_csv('./kakeibo_sample.csv')
df無事読み込まれました。
計算対象 日 内容 ジャンル 金額(円)
0 1 2020/4/1 食材購入 食費 \2,500
1 1 2020/4/1 ゲームソフト 娯楽 \5,500
2 1 2020/4/1 コンビニ(ランチ) 食費 \700
3 1 2020/4/1 コンビニ(ジュース) 食費 \150
4 1 2020/4/1 飲み物 食費 \130
5 1 2020/4/1 飲み物 食費 \130
6 1 2020/4/2 カフェ 食費 \400
7 1 2020/4/2 スマホケース 娯楽 \800
8 1 2020/4/2 食材購入 食費 \1,400
9 1 2020/4/2 飲み物 食費 \200
10 1 2020/4/2 書籍 娯楽 \2,500
11 0 2020/4/3 経費立替 仕事 \5,000
12 1 2020/4/3 カフェ 食費 \300
13 1 2020/4/3 ランチ 食費 \500
14 1 2020/4/4 食材購入 食費 \3,000
15 1 2020/4/4 ラーメン 食費 \850
16 1 2020/4/5 電車賃 交通費 \500
17 1 2020/4/5 カフェ 食費 \450
18 1 2020/4/5 ドラッグストア 日用品 \3,000
19 1 2020/4/5 ランチ 食費 \900
20 1 2020/4/5 パソコンソフト 娯楽 \2,800
21 0 2020/4/5 飲み会立替 娯楽 \9,000
22 1 2020/4/5 タクシー 交通費 \4,500
23 1 2020/4/6 食材購入 食費 \1,500
24 1 2020/4/6 夕飯 食費 \1,200
25 1 2020/4/6 洋服 衣料品 \4,000
26 1 2020/4/7 食材購入 食費 \2,000
27 1 2020/4/7 バス 交通費 \230
28 1 2020/4/7 カフェ 食費 \420
29 1 2020/4/7 飲み物 食費 \120型の変換(必要に応じて行う)
dtypeを使ってデータフレームに格納されたデータの型を確認します。
df.dtypes計算対象 int64
日 object
内容 object
ジャンル object
金額(円) object
dtype: object「計算対象」だけは数値なのでintとして読み込まれています。それ以外は、文字列なのでobject型になっています。
日付はtimestamp形式にしたり、金額は数値にしたりした方が、ピボットテーブルの集計を行う際に便利なので変換しておきます。(例えば、日毎の金額を計算する場合など)
まずは「金額(円)」のカラム。型を数値型に変換する前に「¥2,500」のような表現から、円マークやカンマを削除しておきます。
(※通貨を数値に変換する関数があるのかもしれませんが、ググってもパッと見なかったのでmap関数+独自処理で変換します。)
独自処理の下記の関数を定義。引数として渡された文字列の中に円マークやカンマがあれば削除をしてその値を返すという処理です。
def elim_tuuka(tuuka_str):
return tuuka_str.replace('\\', '').replace(',', '')この関数をmap関数の引数として利用し、「金額(円)」カラムのリストに対してイテレーティブに処理を施します。
list(map(elim_tuuka, list(df['金額(円)'])))map関数の使い方については、以前の記事を参考にします。
結果を表示してみると、正しく円マークやカンマが取り除かれています。
['2500',
'5500',
'700',
'150',
'130',
'130',
'400',
'800',
'1400',
'200',
'2500',
'5000',
'300',
'500',
'3000',
'850',
'500',
'450',
'3000',
'900',
'2800',
'9000',
'4500',
'1500',
'1200',
'4000',
'2000',
'230',
'420',
'120']ということで、dfの「金額(円)」を上記の結果に置き換えます。
df['金額(円)'] = list(map(elim_tuuka, list(df['金額(円)'])))print(df)で置き換え後のdataframeを確認。円マークやカンマが取れているのが確認できます。
計算対象 日 内容 ジャンル 金額(円)
0 1 2020/4/1 食材購入 食費 2500
1 1 2020/4/1 ゲームソフト 娯楽 5500
2 1 2020/4/1 コンビニ(ランチ) 食費 700
3 1 2020/4/1 コンビニ(ジュース) 食費 150
4 1 2020/4/1 飲み物 食費 130
5 1 2020/4/1 飲み物 食費 130
6 1 2020/4/2 カフェ 食費 400
7 1 2020/4/2 スマホケース 娯楽 800
8 1 2020/4/2 食材購入 食費 1400
9 1 2020/4/2 飲み物 食費 200
10 1 2020/4/2 書籍 娯楽 2500
11 0 2020/4/3 経費立替 仕事 5000
12 1 2020/4/3 カフェ 食費 300
13 1 2020/4/3 ランチ 食費 500
14 1 2020/4/4 食材購入 食費 3000
15 1 2020/4/4 ラーメン 食費 850
16 1 2020/4/5 電車賃 交通費 500
17 1 2020/4/5 カフェ 食費 450
18 1 2020/4/5 ドラッグストア 日用品 3000
19 1 2020/4/5 ランチ 食費 900
20 1 2020/4/5 パソコンソフト 娯楽 2800
21 0 2020/4/5 飲み会立替 娯楽 9000
22 1 2020/4/5 タクシー 交通費 4500
23 1 2020/4/6 食材購入 食費 1500
24 1 2020/4/6 夕飯 食費 1200
25 1 2020/4/6 洋服 衣料品 4000
26 1 2020/4/7 食材購入 食費 2000
27 1 2020/4/7 バス 交通費 230
28 1 2020/4/7 カフェ 食費 420
29 1 2020/4/7 飲み物 食費 120この時点では「金額(円)」はまだobject型なので、dtypeの型をint64(pythonのint型に相当)に変換します。
df['金額(円)'] = df['金額(円)'].astype('int64')df.dtypeで型を確認。
df.dtypes計算対象 int64
日 object
内容 object
ジャンル object
金額(円) int64
dtype: object「金額(円)」がint64に変換されているのが確認できます。
ついでに、「日」も文字列になっているのをdatetimeに変換しておきます。
df['日'] = pd.to_datetime(df['日'], errors='ignore')df.dtypeで確認し、datetime型になっているのを確認します。
計算対象 int64
日 datetime64[ns]
内容 object
ジャンル object
金額(円) int64
dtype: objectpivotテーブルを使う
pivotテーブルはpandasのpivot_table関数を使って以下のように使います。(基本的な使い方だけ紹介)
pd.pivot_table(df, index='日', columns='ジャンル', values='金額(円)', aggfunc=np.sum).plot.bar()上記は、indexが日付、カラムにジャンルで値が金額(金額の計算方法は「合計値」)の例です。
ジャンル 交通費 仕事 娯楽 日用品 衣料品 食費
日
2020/4/1 NaN NaN 5500.0 NaN NaN 3610.0
2020/4/2 NaN NaN 3300.0 NaN NaN 2000.0
2020/4/3 NaN 5000.0 NaN NaN NaN 800.0
2020/4/4 NaN NaN NaN NaN NaN 3850.0
2020/4/5 5000.0 NaN 11800.0 3000.0 NaN 1350.0
2020/4/6 NaN NaN NaN NaN 4000.0 2700.0
2020/4/7 230.0 NaN NaN NaN NaN 2540.0ピボットテーブルをグラフ化(棒グラフ)してみます。グラフ化にはplot関数を利用するので、事前に関連モジュールをインポートしておきます。
import matplotlib.pyplot as plt
%matplotlib inline(%matplotlib inlineは、jupyter notebookで実行する場合に書いておく)
以下のように入力します。plot.bar()で棒グラフ生成します。
pd.pivot_table(df, index='日', columns='ジャンル', values='金額(円)', aggfunc=np.sum).plot.bar()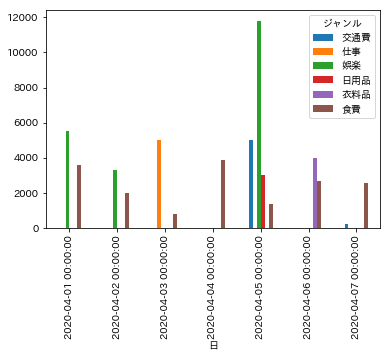
グラフが表示されました。x軸が日付、縦軸が金額、色がジャンルの違いになっています。
まとめ
今回はpivotテーブルをpythonで表示する方法や、そのグラフ化について書きました。エクセルでもpivotテーブルは使えますが、扱えるデータ数が少なかったり、人手を介するので操作が面倒だったりもするので、pythonを使ったpivotテーブルの方が個人的にはおすすめです。
