
こんにちは。カルークです。
今回は、pandas-profiling YData profiling (※)というツールを用いてデータ概要を素早く把握する方法について書きたいと思います。
※ pandas-profilingはYData profilingに名称が変わりました
以前、探索的データ分析(EDA)についての記事を書きましたが、pandas-profiling YData profilingを用いることで更にEDA作業が捗ることでしょう。
YData profilingとは
YData profilingは、pandasのdataframe (エクセルみたいな表形式のデータ)のプロファイリングレポートを作成してくれる便利なツールです。
一昔前は、”pandas profiling”という名前でしたが、YData profilingに名称が変わりました。
昔YData profilingを知らなかった頃の私は、shapeやvalue_counts()、isnull()、相関図など色々な関数を駆使して手動でレポート作成していましたが面倒でした。
YData profilingを使うと一行でそういった面倒な出力をまとめてやってくれるので、今は新しいデータを手に入れたらまずはYData profilingにかけています。
YData profilingについて詳しくは公式ドキュメントをご覧下さい。
今回用いるデータセット
今回用いるデータセットは、Kaggleのタイタニックデータセットです。データ分析、機械学習に携わる方にとっては言わずと知れた有名なデータセットですね。
YData profilingの入力データとして、titanicデータのtrain.csvを用います。
データのダウンロード方法については、以前書いた記事にまとめてあります。
YData profilingのインストール
まずはYData profilingをpipでインストールします(初回のみ)。
pip install ydata-profilingconda環境の人は以下のコマンドになります。
conda install -c conda-forge ydata-profilingYData profilingのインポート
ここからはpythonのnotebook上でのコード(.ipynb)になります。
最初にYData profilingをインポートします。numpy, pandasもまとめてインポートしておきましょう。
import numpy as np
import pandas as pd
from ydata_profiling import ProfileReportデータの読み込み
続いてデータを読み込みます。
さきほどダウンロードしたtitanicのデータ(zip形式)を展開するとtrain.csvが入っているので、このファイルを任意のフォルダに移動しておきます。今回は、実行中のnotebook(.ipynbファイル)と同じ階層に”data”というフォルダを作成してその中に入れておきます。
csvの読み込みはpandasのread_csv()を用います。
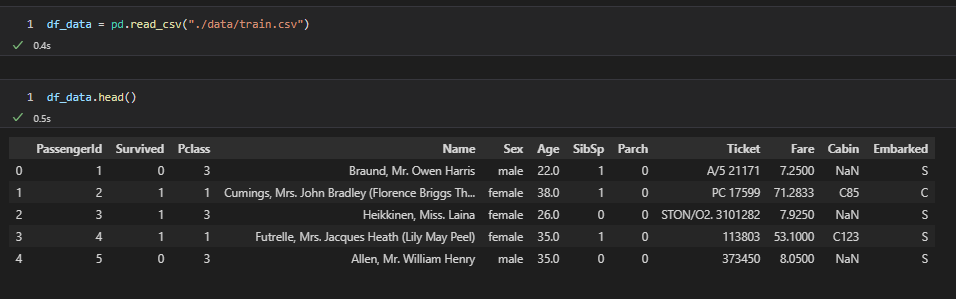
df_data = pd.read_csv("./data/train.csv")無事にデータの読み込みが出来たかを.head()で確認してみます。
YData profilingのレポートを作成
それではいよいよYData profilingのレポートを作成してみたいと思います。
レポート作成といっても、以下の一行を実行するだけで、profilingが作成されます。簡単ですね!(titleは適当に変えてもらって構いません)
profile = ProfileReport(df_data, title="Titanic data profiling Report")実行時間は環境やデータサイズに依りますが、今回用いるデータセット(891行12列)だと私のPC(普通スペック)で数秒で実行できました。
YData profilingのレポートを確認
出来上がったprofilingを出力してみましょう。先程作成したプロファイルの変数名(“profile”)をセルに入れて実行します。
しばらくすると以下のようなレポートが表示されます。ちなみに実行はvscode上で行っています。
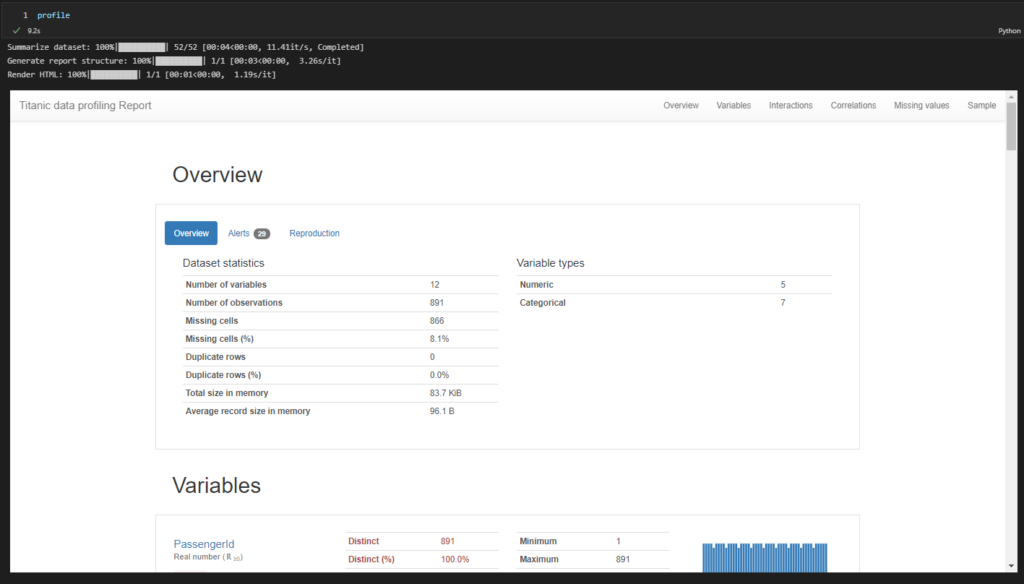
Overview
Overview
Overviewでは、データの統計情報の概要を表示してくれます。レコード数やカラム数、欠損値の件数、割合、重複するレコード数などです。
Alearts
続いて、Aleartsというボタンを選択してみます。こちらでは、各カラムについて前処理で注意すべき点を自動で抽出してくれているようです。
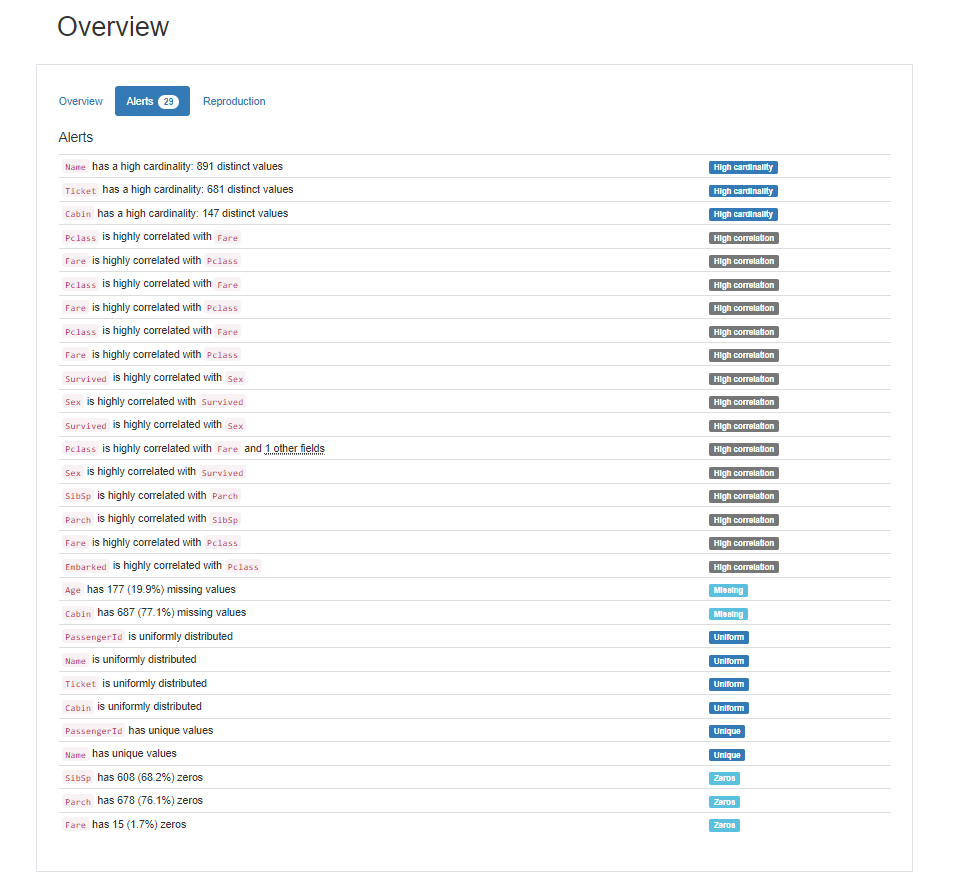
重複してしまっているレコード数(duplicate row)、カラムごとのカーディナリティ(cardinality)の度合い、カラム同士の相関(correlation)の強さ、欠損値(missing value)の数、データの偏り(skewed)などが表示されます。
こういった情報がわかると、feature engineeringでの様々な仮説を立てることができます。以下はそうした仮説の一例です。
- 「このカラムは欠損が多いから使い物にならない。カラムごと削除しよう」
- 「このカラムは欠損が少ないな。欠損値はひとまず平均値で埋めよう」
- 「このカラムのカーディナリティは高い。カテゴリをクラスタリングして、カテゴリ数を減らしてみよう」
- 「このカラムはカーディナリティが高いな。…と思ったけど、これはIDのカラムだから問題ないな」
- 「このデータセットは正解ラベルのデータの偏りが激しいインバランスデータだ。オーバーサンプリングやアンダーサンプリングを試してみよう。」
- 「インバランスデータだから、sample weightでコスト関数を調整しよう」
- 「このカラム同士は相関が強いから、マルチコ(多重共線性)の恐れがありそうだ。そのまま用いると精度が落ちそうだから、片方をカラムごと削除してしまおう」
- 「このカラムは正解と相関が強いな。ターゲットリーケージなので実際の推論時には手に入らないのかもしれない。お客さんに確認が必要だが、ひとまず学習データに含めるのはやめておこう。」
Reproduction
続いてReproductionというボタンを押してみます。こちらでは、pandas-profilingレポートの作成開始日、終了日、レポート作成実行時間、pandas-profilingのバージョンなどが表示されています。
Variables
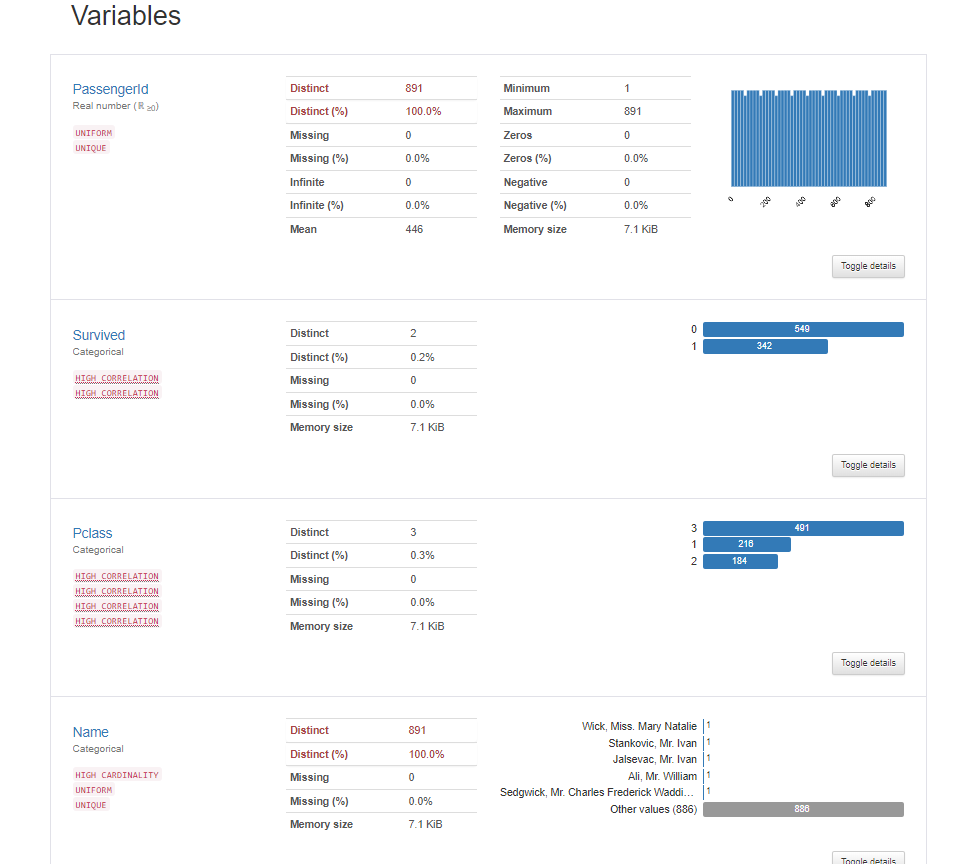
続いてVariablesです。Variablesでは、各カラムの詳細をレポートしてくれています。
カテゴリカル変数の場合と、数値型変数の場合で表示内容が若干異なります。
数値型変数の場合
数値型の例として、”Age”を見てみます。
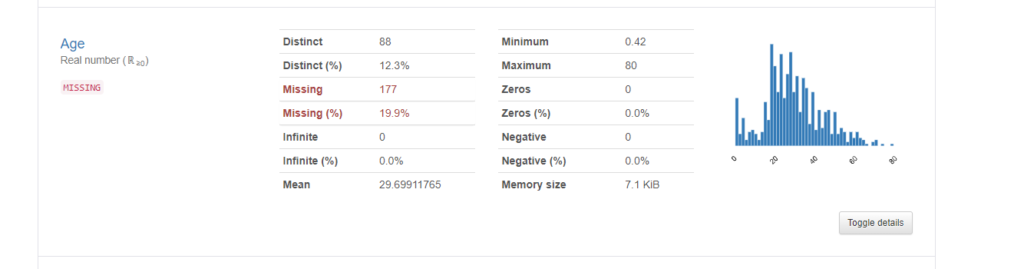
Distinct情報より、88種類の値があるようです。また、Missing情報から、177件の欠損(割合にして19.9%)があることが分かります。平均年齢は29.7歳、最長年齢80歳、最年少が0.42歳(なぜか小数)です。右下にある”Toggle details”を押すともう少し細かな情報が表示されます。
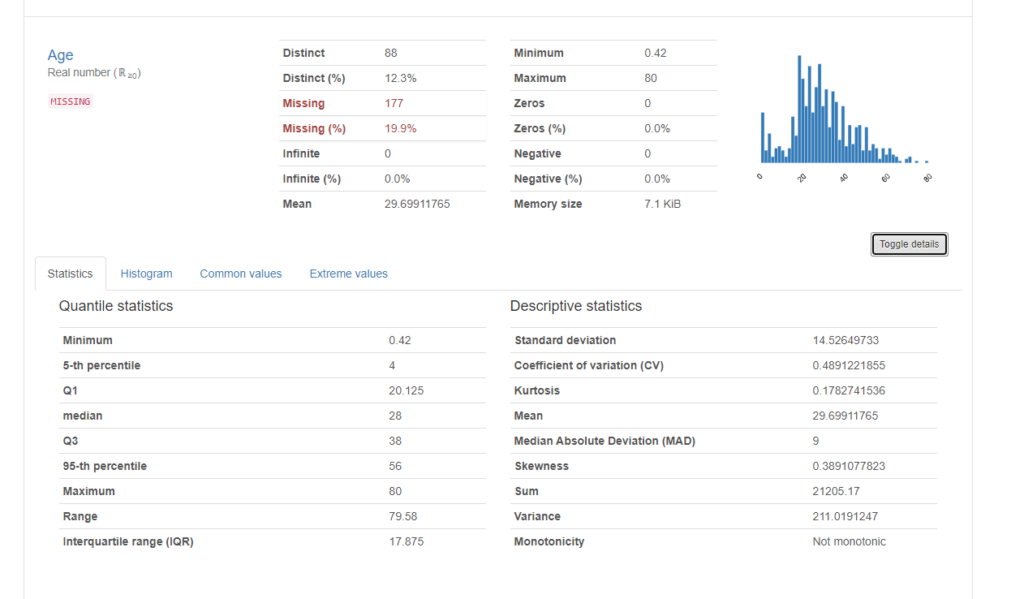
Statistics
Statisticsでは、先程の最年少、最長年齢などの他に四分位点の値や中央値、年齢範囲、標準偏差など様々な情報が表示されます。
Histgram
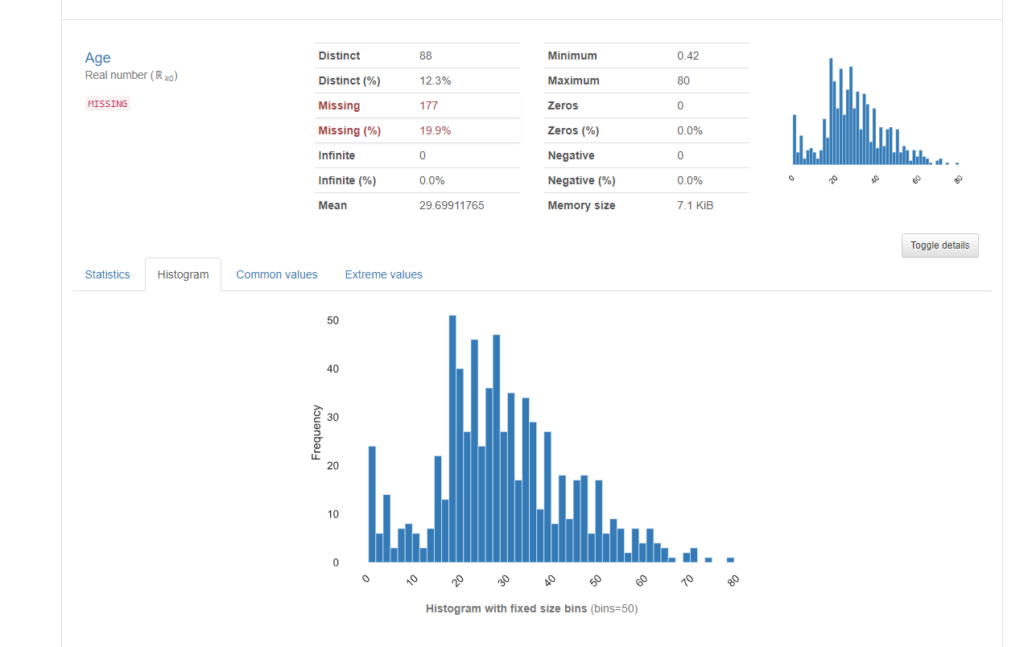
Histgramのタブを押すと、ヒストグラムが表示されます。これは”Toggle details”を押す前に既に表示されているヒストグラムと同じものですね。
Common values
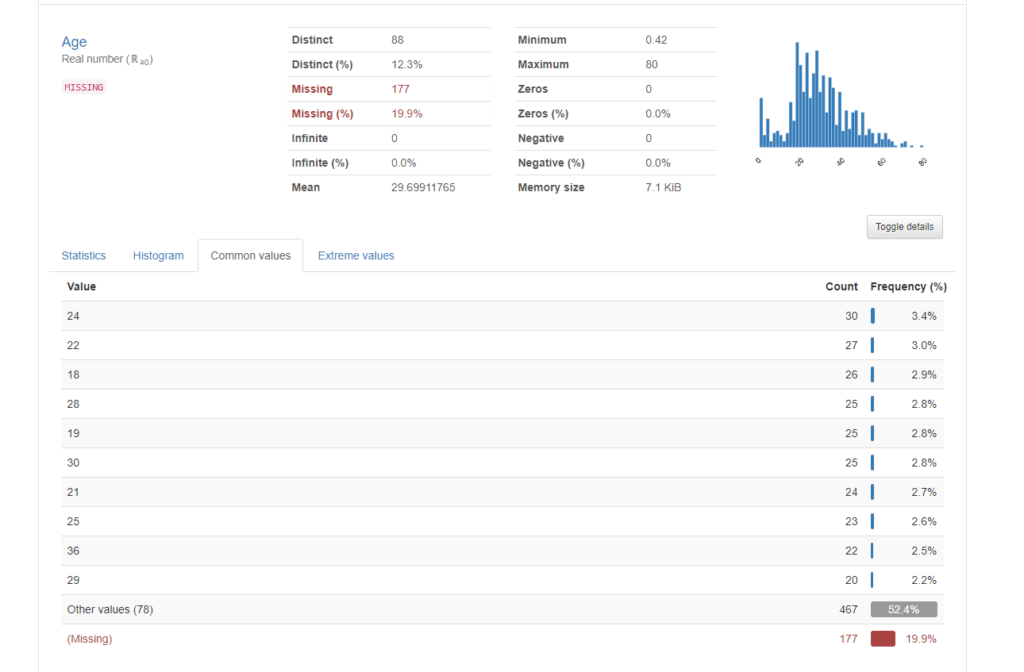
Common valuesでは、頻度の高い値(降順)に件数と割合のtop 10が表示されます。top 11以降は”Other values”としてまるっと一括にされていますね。それから一番下に赤色で表示されているのは、Missing value(欠損値)です。頻度の割合が棒グラフで出ているので、直感的でわかりやすいですね。ちなみにコードだと、df_data[“Age”].value_counts(dropna=False)で同じ情報が得られます。
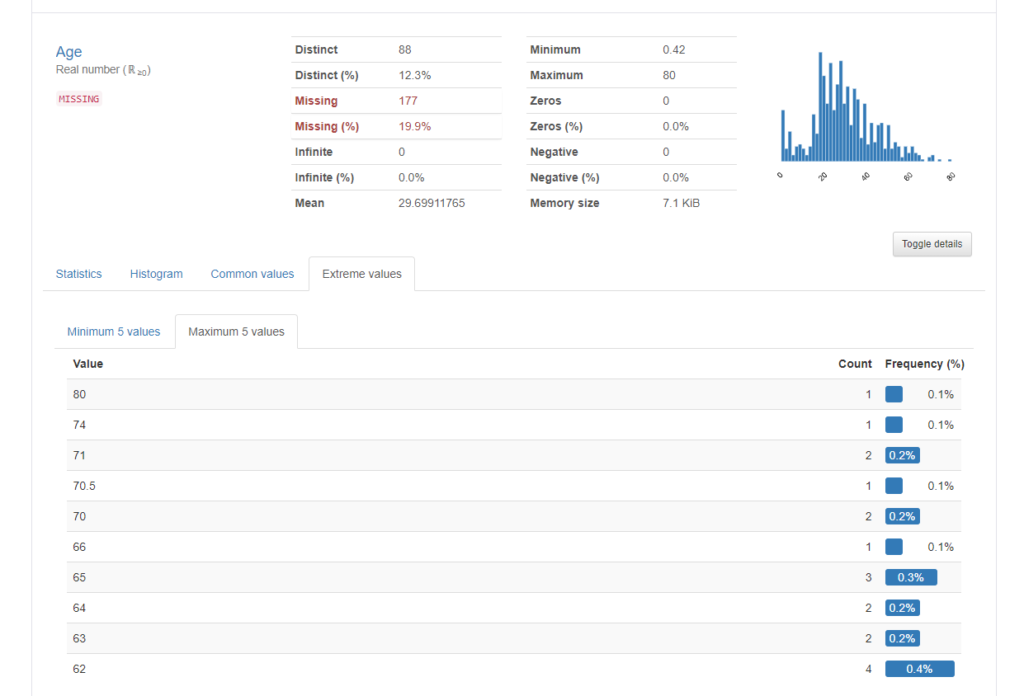
Extreme values
“Extreme values”タブでは、値が極端に小さいもの、極端に大きいものを抽出してくれます。”Minimum 5 values”では、値が小さいもの順に頻度と共に表示してくれます。”Maximum 5 values”は逆に値の大きいものから順に頻度と一緒に表示してくれます。
Minimum 5 values
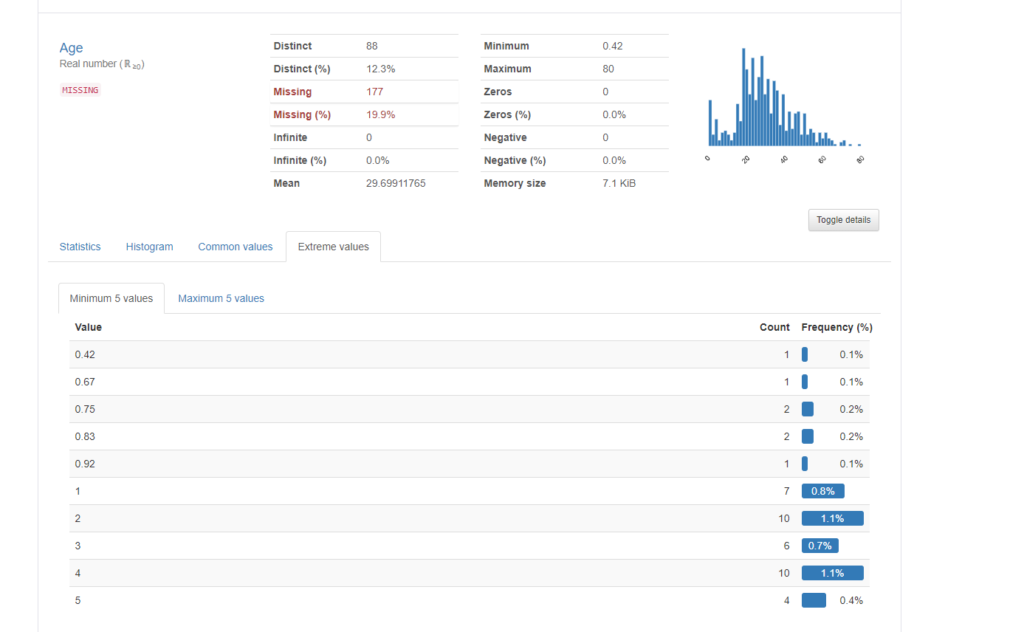
Maximum 5 values
カテゴリカル変数の場合
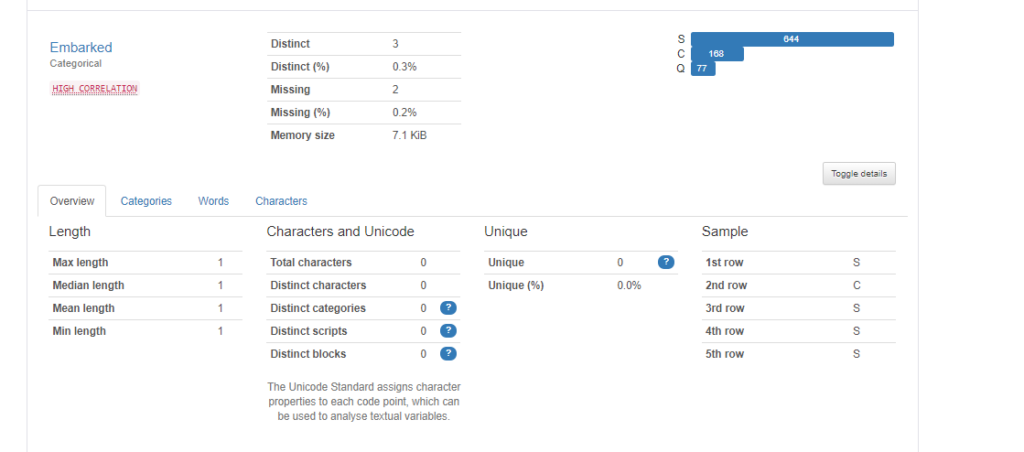
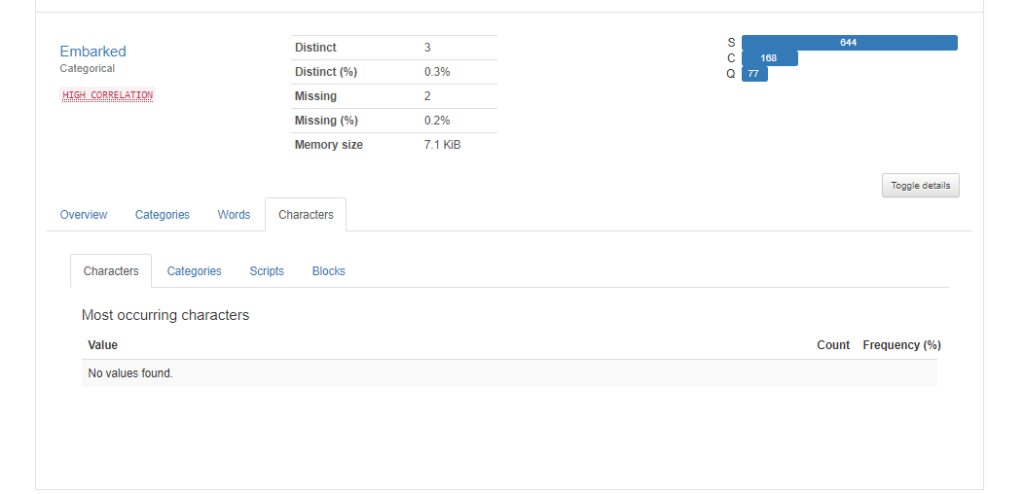
続いてカテゴリカル変数です。例えば、”Embarked”カラム(出港した港の名前)では以下のように表示されます。それぞれの値の意味はC = Cherbourg、Q = Queenstown、S = Southamptonですが、Southamptonが多いのが分かりますね。また、2件の欠損値があることなども分かります。

更に右下にある”Toggle details”をクリックすると、より詳細な情報が分かります。
Overview
“toggle details”のOverviewを見てみます。”Embarked”カラムは文字列ですが、登場する最大文字数(Max length)、最小文字数(Min length)、それらの中央値(Median), 平均値(Mean)などの情報があります。S, C, Qの3つしかないので、今回はすべて1ですね。(例が良くなかった・・・)
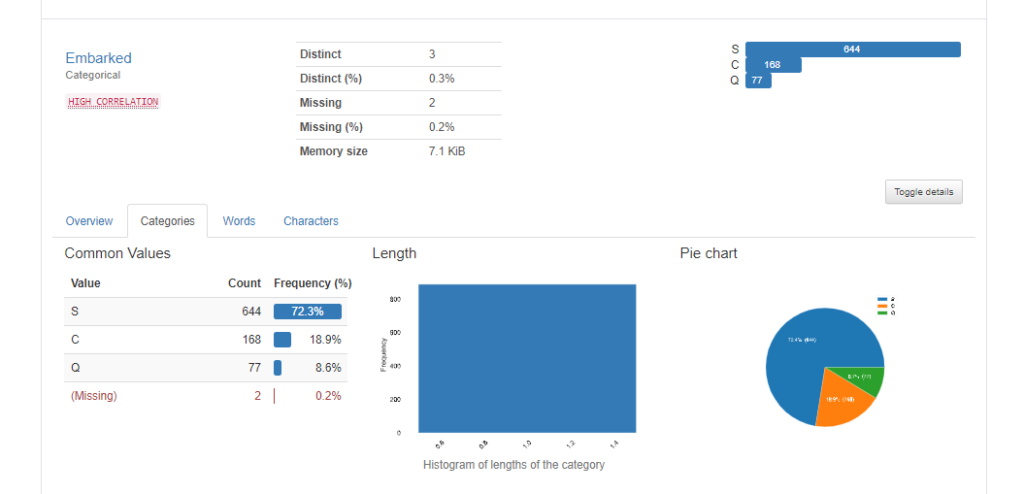
Categories
Categoriesのタブを選択してみます。すると、value毎の頻度と登場割合が数値およびヒストグラムとして表示されます。数値の時と同様、赤色で欠損値が表示されています。2件が欠損していますね。
ちなみにコードだと、df_data[“Embarked”].value_counts(dropna=False)で同じ情報が得られます。
また、円グラフで割合が可視化されています。
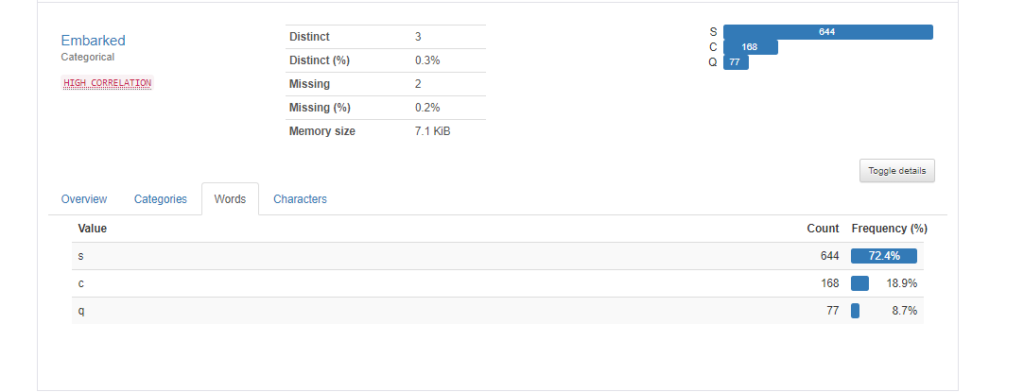
Words
Wordsを選択してみます。Wordsでは、単語単位に分割された状態で頻度の計算をしてくれます。例えば、”United States”なら”United”と”States”で分割されてそれぞれの頻度が表示されるイメージです。ただtitanicのEmbarkedのS, C, Qはこれ以上分割できないので、CategoriesもWordsも同じ結果になっています。(例が良くなかった・・・)
Characters
Charactersでは、”Most occurring characters”, “Most occurring Categories”, “Most occurring Scripts”, “Most occurring Blocks”の件数、割合が表示されるようですが、今回はNo values foundです。
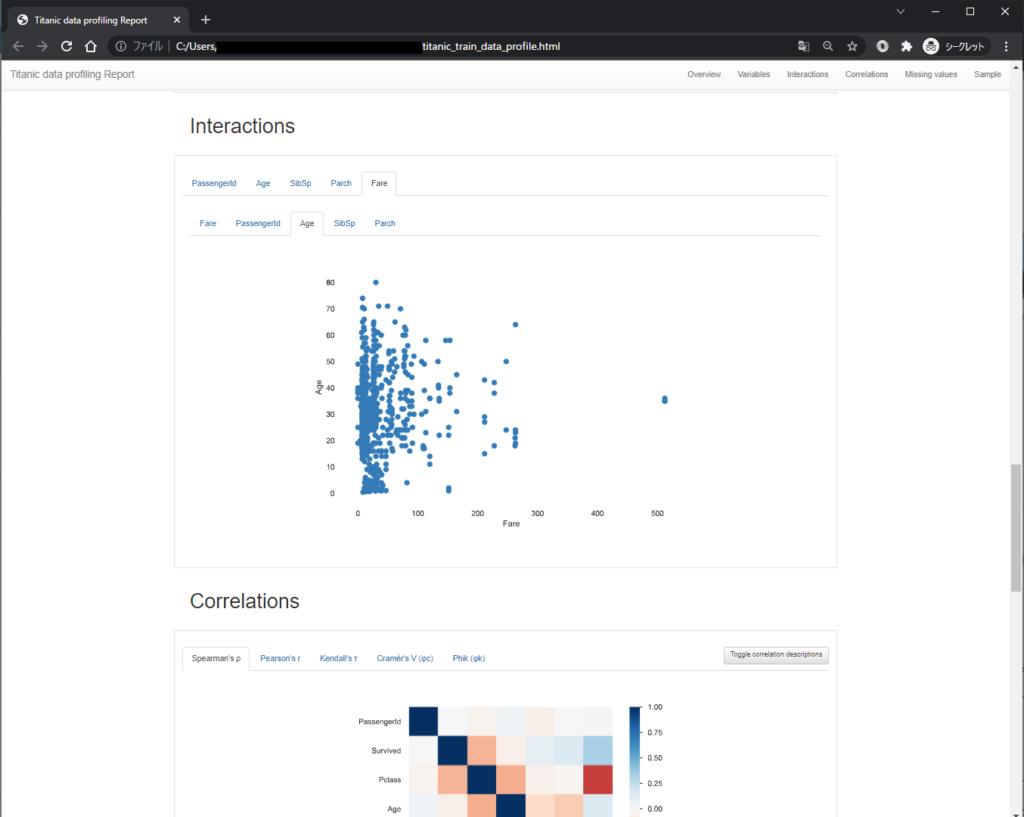
Interactions
Interactionsでは、数値系のカラムについて、2つのカラム間の関係性を散布図としてプロットできます。X軸、Y軸をタブで動的に切り替えることが出来ます。
以下は、Age(年齢)とFare(運賃)をそれぞれX軸、Y軸に設定してプロットした図です。
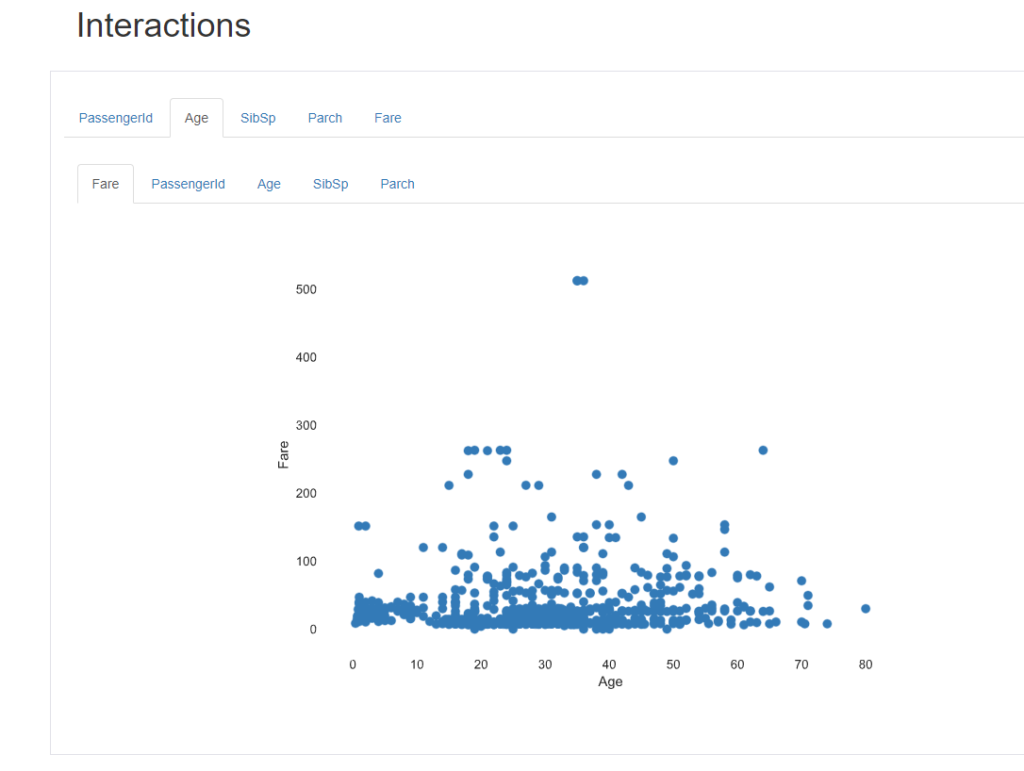
「年齢が高いと運賃も高いのかと思ったが、そうでもないみたいだ」みたいな分析がマウスクリックだけで出来るのは便利ですね。
Correlations
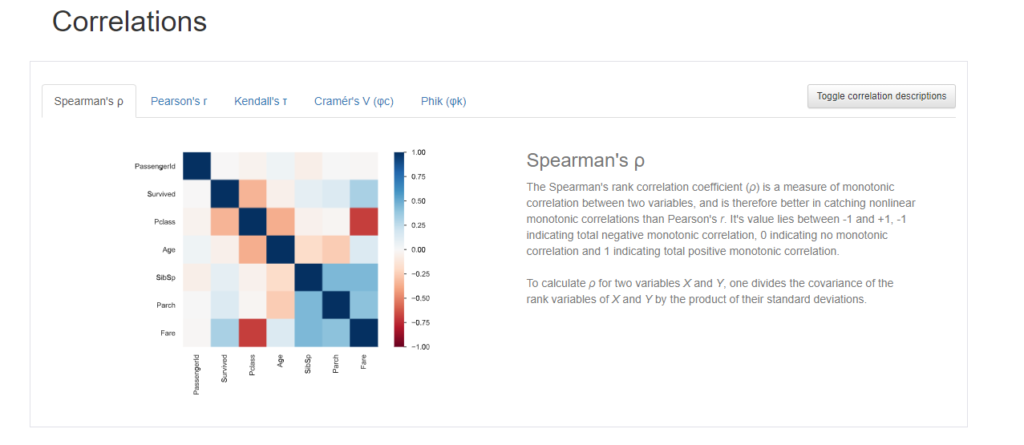
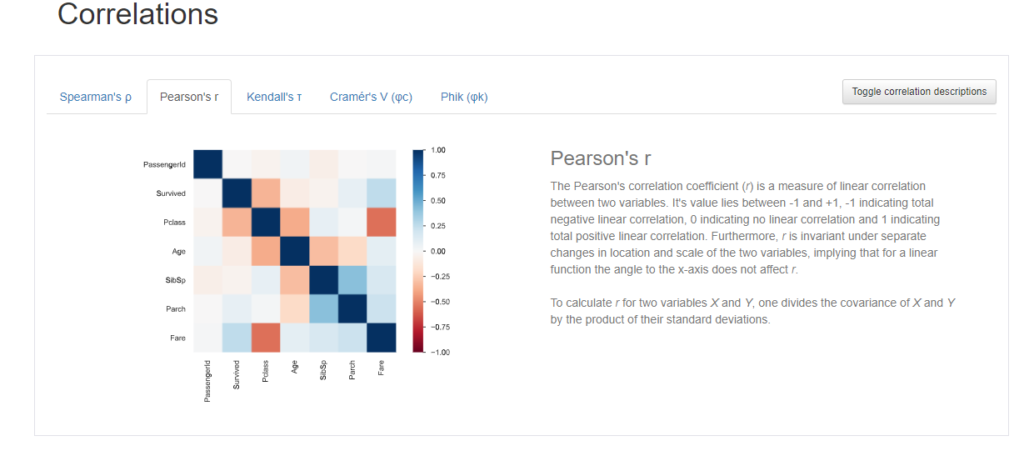
Correlationsは、カラム同士の相関をヒートマップで可視化してくれています。
相関係数にも色々ありますが、YData profilingでは以下の相関係数を選択することができます。
- スピアマンの相関係数(数値変数同士の相関係数)
- ピアソンの相関係数(数値変数同士の相関係数)
- ケンドールの相関係数(数値変数同士の相関係数)
- クラメールの連関係数(カテゴリカル変数同士の相関係数)
- Phikの相関係数(数値、カテゴリカル混同)
以下にそれぞれの相関係数を選んだときの出力結果を載せます。ちなみに、横にある”Toggle correlation descriptions”を押すと、各相関係数の説明が表示されるので、それも一緒に載せておきます。
スピアマンの相関係数
ピアソンの相関係数
ケンドールの相関係数
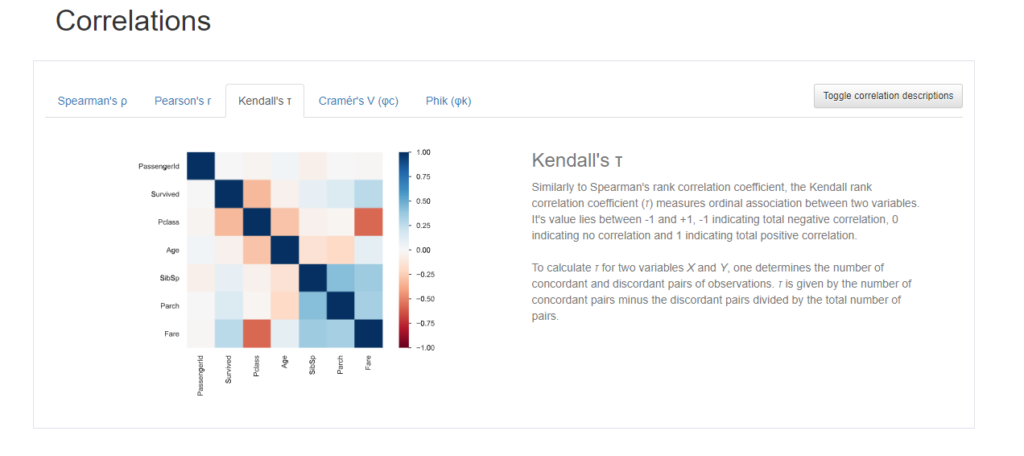
クラメールの 連関係数
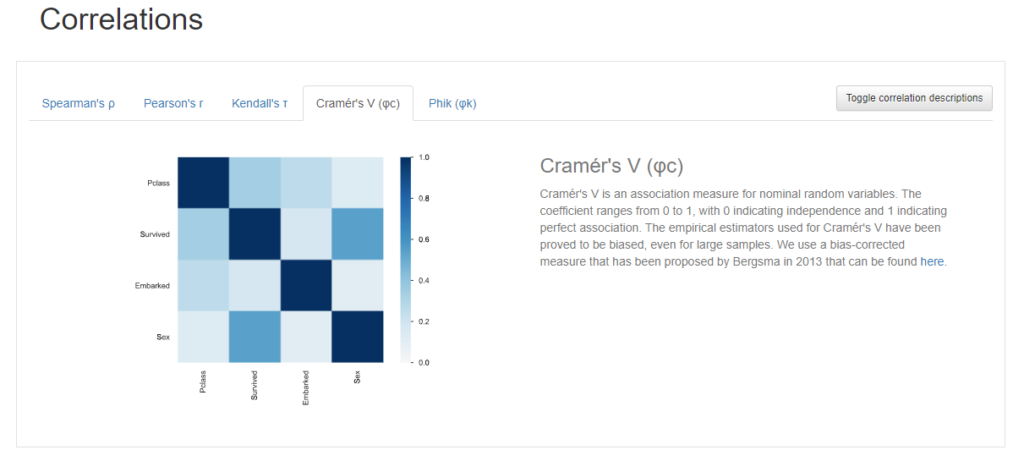
Phikの相関係数
相関といったら数値型のカラム同士でしか出せないと思っていたのですが、クラメールの相関係数やPhikの相関係数の結果を見るとカテゴリカル変数同士や数値・カテゴリカル混同での相関も出せるのですね。
Missing values
“Missing values”では、各カラム毎の欠損値に関する詳細な分析をしてくれます。
Count
Countタブをクリックすると、各カラム毎の欠損値件数を棒グラフで表示してくれます。
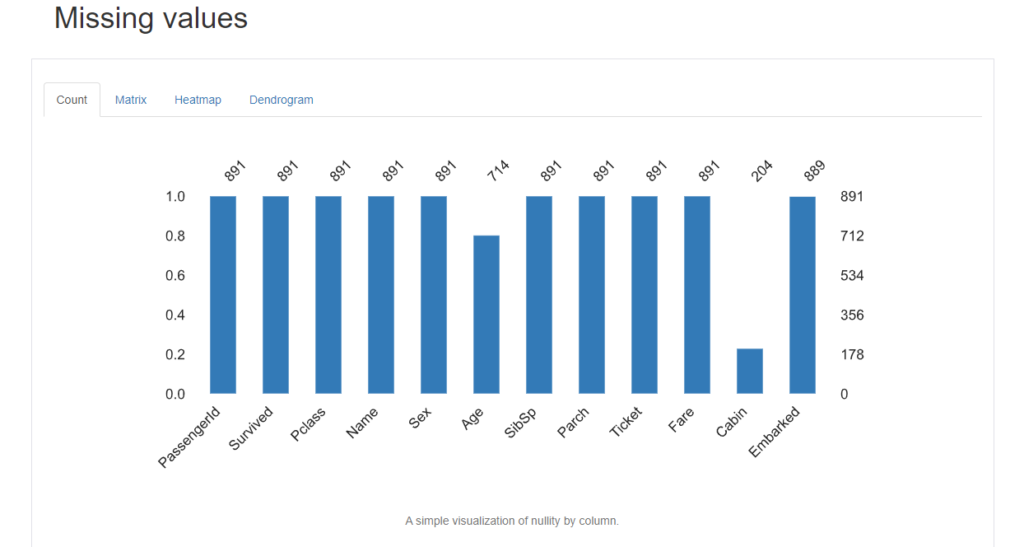
Age, Cabinは他よりも欠損値が少ないみたいですね。
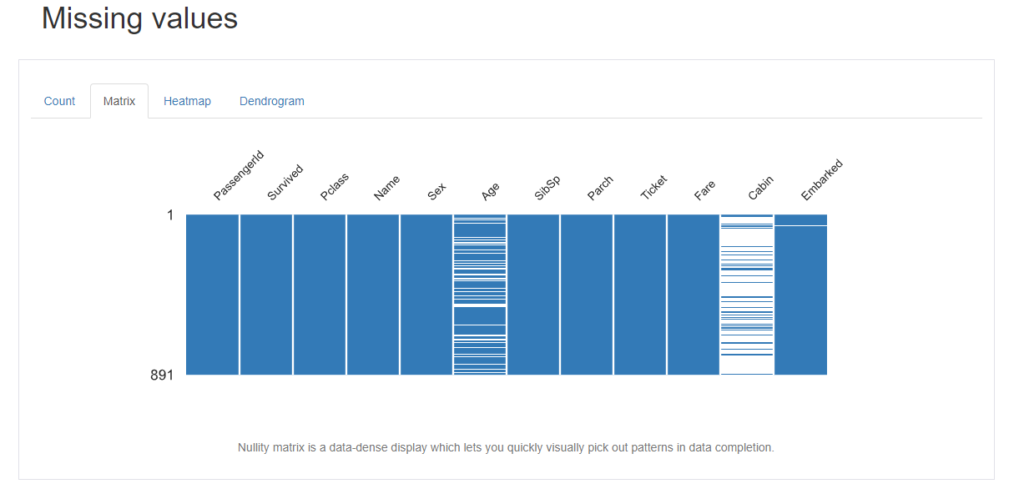
Matrix
Matrixをクリックすると、Nullity matrixを表示してくれます。Nullity matrixは、データ補完のパターンを視覚的に素早く拾い出すことができる、データ密度の高い表示です。
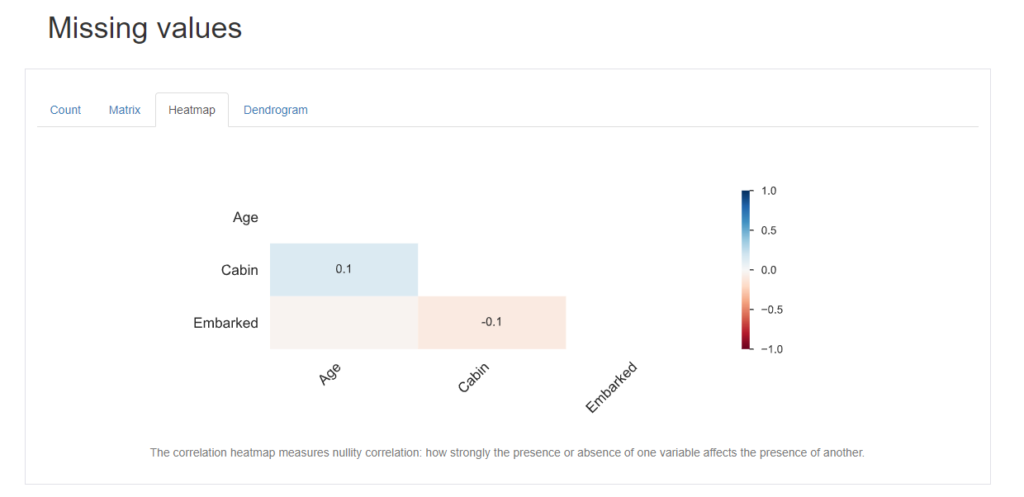
Heatmap
Heatmapをクリックすると、各カラムの欠損値毎の相関をヒートマップで表示してくれます。
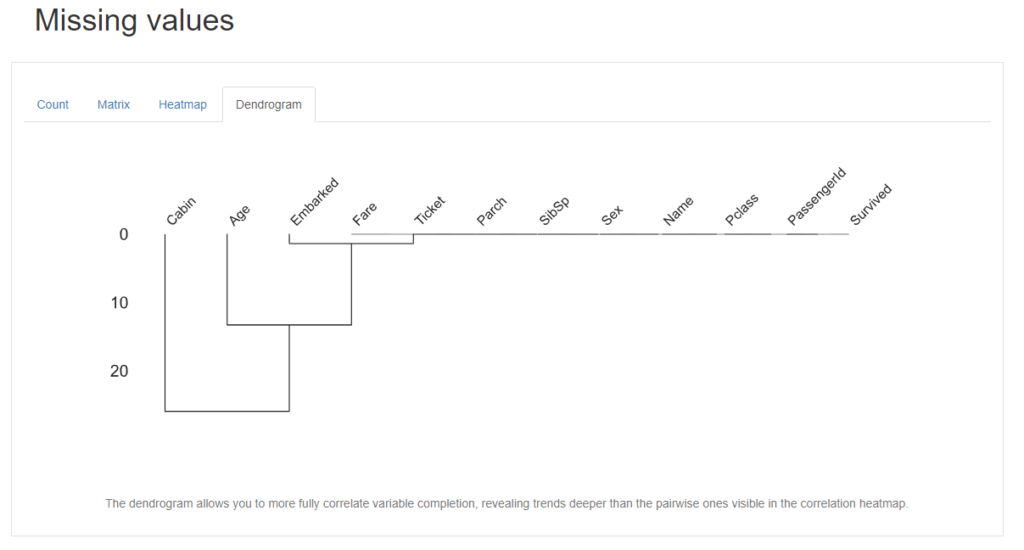
Dendrogram
最後にDendrogram(樹形図)です。デンドログラムは、変数の補完をより完全に相関させることができ、相関ヒートマップで見えるペアワイズよりも深い傾向を明らかにすることができます。
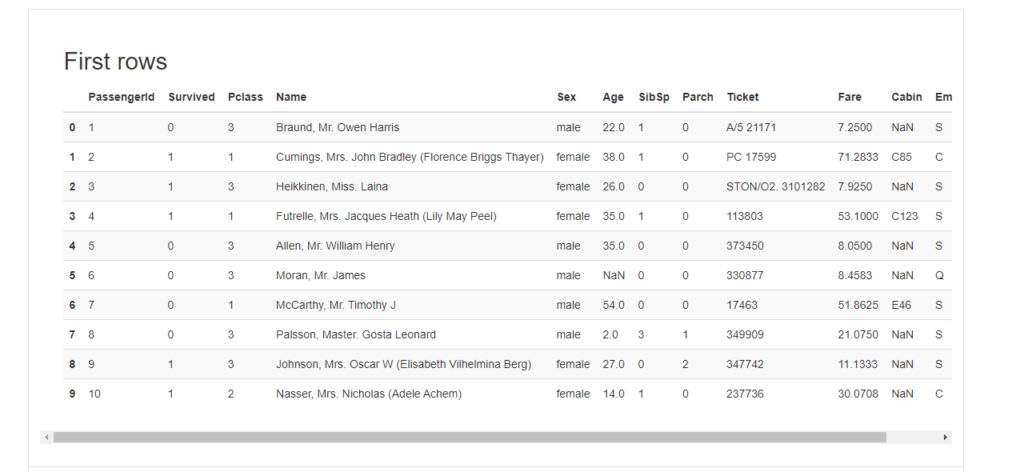
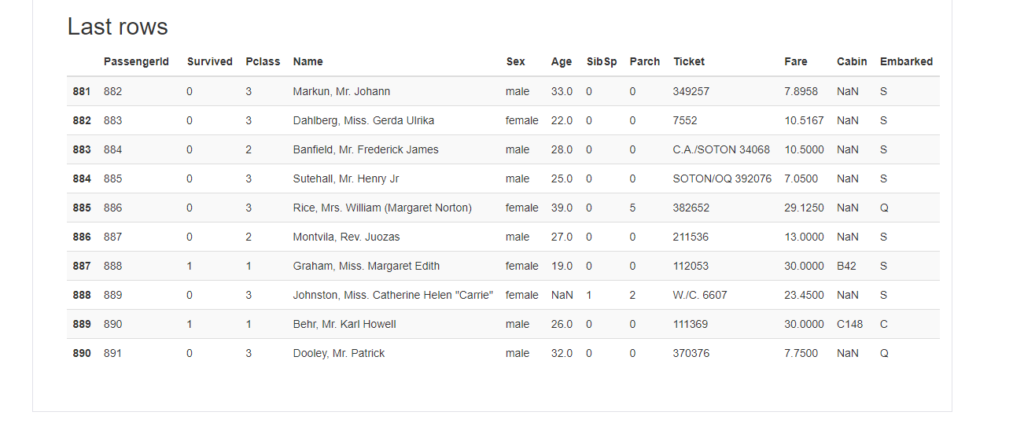
Sample
“Sample”は実際のデータの冒頭(head)と最後(tail)を10件ずつ表示してくれています。これは、dataframeに対する操作である.head(10)や.tail(10)でも同じ結果を表示させることができますね。
First rows
Last rows
YData profilingのレポートをhtml形式で出力
ここまでで、profilingのレポート内容にどのようなものが含まれるかを紹介しました。実際、レポートの中身を見てみると結果は非常に綺麗に纏まっていて、そのままお客さんや上司、同僚へのレポートとして使いたくなりますね。そんなときは、to_file()というメソッドを用いることで先程notebook上で見ていたレポート内容をそのままhtml形式にする事が出来るんです。(便利)
profile.to_file("./titanic_train_data_profile.html")
こんな感じでファイル出力されているのが確認できます。

実際にブラウザ(Chrome)で開いてみると、notebookで出力していたレポートがそのままブラウザでも見れるのが確認できます。もちろんタグやボタンによる動的な表示切り替えもそのまま出来ます。
まとめ
今回は、YData profilingを用いてデータの概要をサクッと可視化する方法についてまとめました。どんなデータでもまずはデータ理解、探索的データ分析(EDA)が大切ですが、YData profilingを用いると様々な切り口でデータの概要を簡単に知ることが出来るので、今後も重宝しそうです。
