こんにちは。カルークです。
今日はpandasを用いたテーブルデータの概要(サマリー)を把握する流れについて、自分の備忘録も兼ねてまとめたいと思います。
ちなみにpandasとはpython環境でのデータ解析ライブラリで、機械学習やデータサイエンスの分野では広く使われています。
- 実行環境
- 用いるデータセット
- 前準備(pandasのインストール)
- pandasでテーブルデータの概要を出力
- pandasのインポート
- データの読み込み
- データを表示する(”head()”または”tail()”)
- データのサイズを調べる(”shape”)
- データのサイズ(行数、列数)、欠損値情報、メモリ使用量を一括取得(”info()”)
- データの型を調べる(”dtypes”)
- 時間情報を扱いやすいようにobject型からdatetime型に変換する(”to_datetime()”)
- データの値の概要を把握する:数値型(”describe()”)
- データの値の概要を把握する:数値以外(”describe(exclude=’number’)”)
- datetime型のデータ期間、日数の把握(”max()”, “min()”)
- 欠損値を調べる(”isnull().sum()”)
- 値の出現頻度を算出する(”value_counts()”)
- まとめ
実行環境
今回の実行環境は以下になります。
- OS: Windows 10 Pro (64-bit)
- Anaconda: conda version 4.9.2
- Python: 3.8
- 実行環境: jupyter notebook
- pandas: 1.2.3
用いるデータセット
今回学習用に用いたデータセットは、KaggleのE-Commerce Dataです。こちらのデータセットですが、イギリスに拠点を置く無店舗型オンライン小売業者の全ての取引を含んでいるデータで、期間は2010年12月1日から2011年12月9日との事です。(”Data”タブの”Description”の所に記述されています)
Dataタブを選択し、”train.csv”を予めダウンロードしておきます。データサイズは約45MBです。
なお、kaggleのユーザアカウントをお持ちでない場合は作成が必要です。
なお、本記事ではデータそのものに対する説明は行いません。
前準備(pandasのインストール)
pandasがインストールされていない場合、事前にインストールする必要があります。
Anacondaを利用している場合、Anaconda promptを起動して以下のコマンドを入力します。
conda install -c anaconda pandasAnaconda以外の場合は、以下のコマンドを入力します。
pip install pandaspandasでテーブルデータの概要を出力
ここからが本題です。以下では、pandasを用いてテーブルデータのサマリーを出してみたいと思います。
pandasのインポート
まずはpandasをインポートします。
import pandas as pdデータの読み込み
続いてデータを読み込みます。ここでは、実行するnotebook (.ipynb)と同じ階層に”data”というフォルダを作成し、その中に先程ダウンロードした”data.csv”を配置したとします。
pandasのread_csvというメソッドを利用するとcsvをdataframeの形式に変換してくれるので、そのdataframeをdf_ecomerceという変数に格納します。
df_ecomerce = pd.read_csv("./data/data.csv")以下では、このdf_ecomerceに対して各種操作を行っていきます。
データを表示する(”head()”または”tail()”)
まずは読み込んだデータを表示してみます。データを上からN件表示したい場合は”head(N)”、下からN件表示したい場合は”tail(N)”を使います。なお、デフォルトでN=5なので、カッコの中の数字を省略した場合は5件が出力されます。
head():
df_ecomerce.head()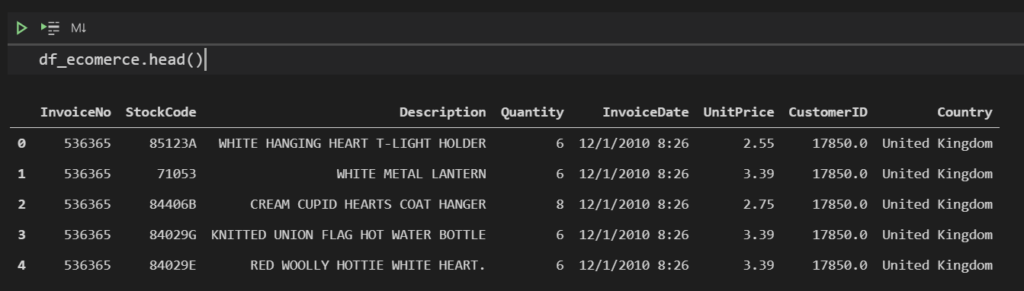
tail():
df_ecomerce.tail()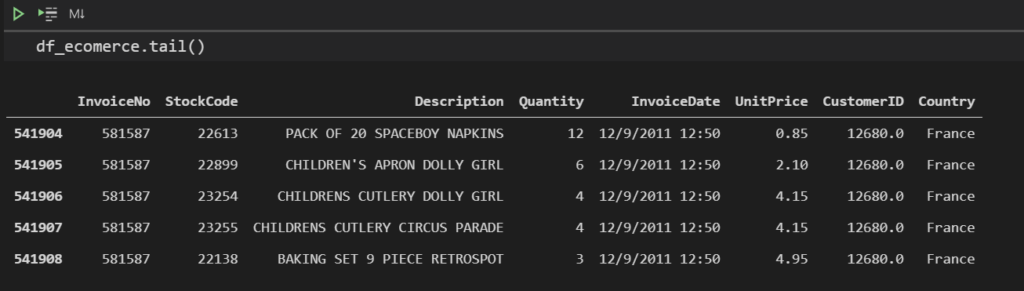
10件表示したい場合は、カッコの中に10を入れて実行すれば表示されます。
df_ecomerce.head(10)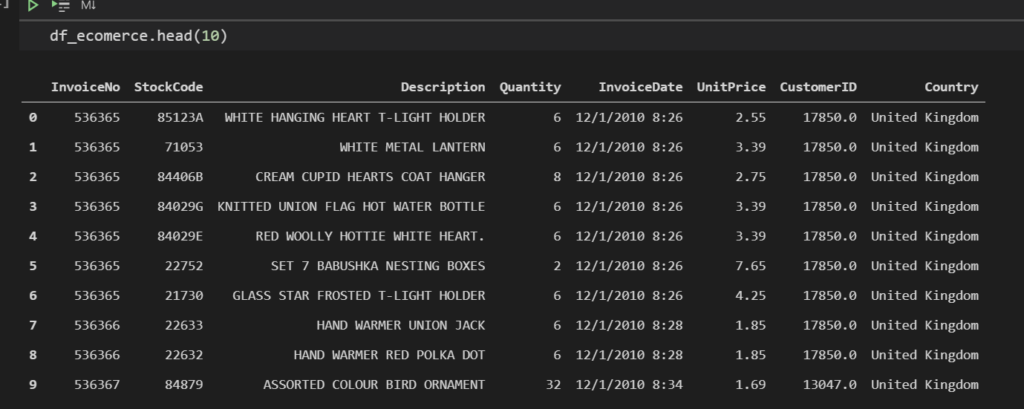
データのサイズを調べる(”shape”)
手っ取り早くdataframeのサイズ(行数、列数)を知るには”shape”が簡単です。
df_ecomerce.shape# 出力
(541909, 8)レコードが541909行、カラムが8列ということが分かります。
データのサイズ(行数、列数)、欠損値情報、メモリ使用量を一括取得(”info()”)
先程のshapeでは、dataframeのサイズ(行数、列数)だけを取得しましたが、他にも欠損値情報やメモリ使用量などを一括で取得するメソッドがあります。それが”info()”です。
df_ecomerce.info()# 出力
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 541909 entries, 0 to 541908
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 InvoiceNo 541909 non-null object
1 StockCode 541909 non-null object
2 Description 540455 non-null object
3 Quantity 541909 non-null int64
4 InvoiceDate 541909 non-null object
5 UnitPrice 541909 non-null float64
6 CustomerID 406829 non-null float64
7 Country 541909 non-null object
dtypes: float64(2), int64(1), object(5)
memory usage: 33.1+ MBインデックス数(行数)が541909、カラム数が8という情報の他にも、各カラム毎に欠損値がどれくらいあるか、各カラムの型、メモリ使用量 33.1MBといった、様々な情報が出力されます。
データの型を調べる(”dtypes”)
ちなみに、”dtypes”を用いても、各変数の型を調べる事が出来ます。
df_ecomerce.dtypes# 出力
InvoiceNo object
StockCode object
Description object
Quantity int64
InvoiceDate object
UnitPrice float64
CustomerID float64
Country object
dtype: object時間情報を扱いやすいようにobject型からdatetime型に変換する(”to_datetime()”)
df_ecomerceには、時間に関するカラム(”InvoiceDate”)が含まれているようです。さきほど、dtypesでも確認した通りこのカラムはobject型になっており、文字列として認識されているようです。
(以下の図は、”.head()”の再掲です)
時間として扱いやすいようにobject型からdatetime型に型変換を行います。
datetime型への変換には、”to_datetime()”のメソッドを用います。以下のコマンドを実行することで、”InvoiceDate”カラムをdatetime型に変換し、それを”InvoiceDate”のカラムに上書きする事ができます。(もちろん、新しいカラムを追加してその中に保存しても良いです)
df_ecomerce["InvoiceDate"] = pd.to_datetime(df_ecomerce["InvoiceDate"])改めて型を確認してみます。
df_ecomerce.dtypes# 出力
InvoiceNo object
StockCode object
Description object
Quantity int64
InvoiceDate datetime64[ns] # ← 型が変換されているのが確認できる
UnitPrice float64
CustomerID float64
Country object
dtype: object“InvoiceDate”がdatetime64[ns]になっているのが確認できました。
一応、値としてはどうなっているのかも見てみます。
df_ecomerce.head()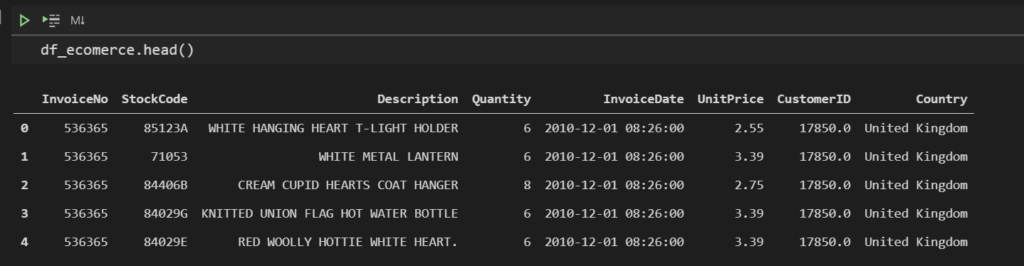
1レコード目の”InvoiceDate”で見てみると、object型の時は”12/1/2010 8:26″という値が入っておりましたが、datetime型へ変換した後は”2010-12-01 08:26:00″というようにフォーマットが変わっているのが分かります。
どうやって年月日日時を同定してくれるのか?
ちなみに変換前の値でどれが年、どれが月、どれが日、どれが時間、どれが分かをどうやって分かるのか気になるかもしれませんが、一般的な記述の仕方であればto_datetimeの中でいい感じに年月日日時を同定してdatetime型に変換してくれます。データによっては書き方が独特で、いい感じに年月日日時の同定が出来ない場合もあるかと思いますが、その場合はformatという引数に、そのフォーマットを定義してあげる事でdatetime型に変換することができます。
詳しくは以下の記事をご覧ください。
データの値の概要を把握する:数値型(”describe()”)
データの値の概要(このカラムの平均値はこれくらいで、最大値はこれくらいで、、など)を知るには”describe()”を用います。
df_ecomerce.describe()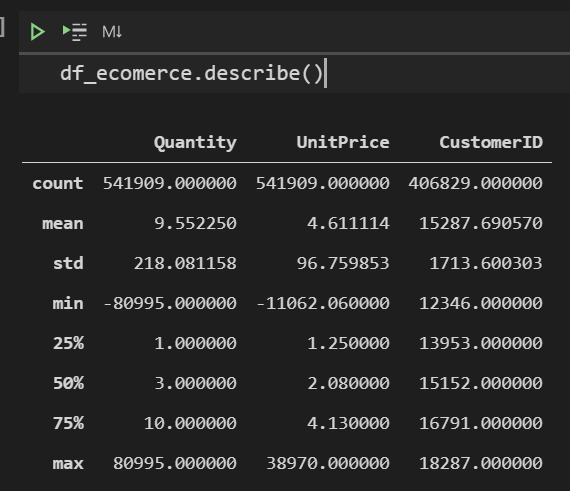
describe()で出力されるのは、数値のカラム(型がintやfloat)のみになります。ここでは、”Quantity”, “UnitPrice”, “CustomerID”が対象となります。それらの値について、count(値の数)、mean(平均値)、std(標準偏差)、min(最小値)、25%(1/4分位数)、50%(中央値)、75%(3/4分位数)、max(最大値)の集計結果が表示されます。
データの値の概要を把握する:数値以外(”describe(exclude=’number’)”)
describe関数の引数でexclude=”number”を指定すると、数値以外の値の概要を出力することが出来ます。
df_ecomerce.describe(exclude="number")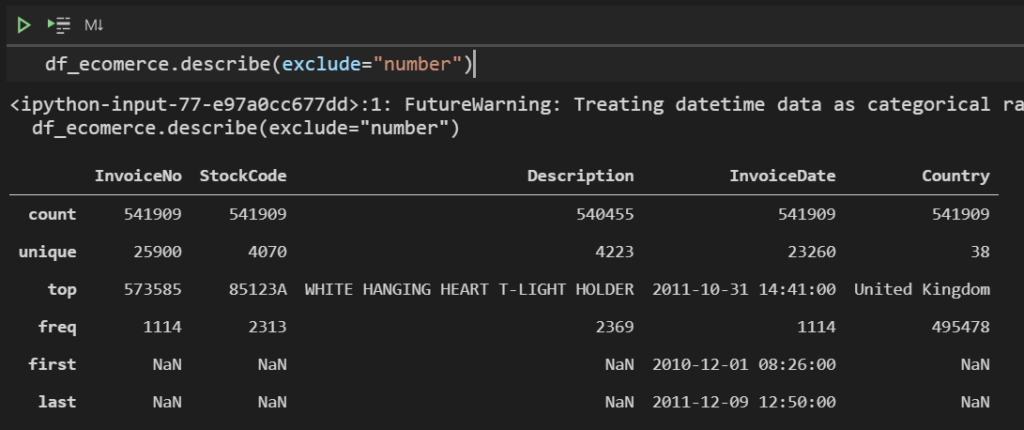
このように文字列のカラムの概要を知ることが出来ます。それぞれ、count(出現回数)、unique(値のユニーク数)、top(最も多く登場している値)、freq(その頻度)の情報が取得できます。
ちなみに、さきほどInvoiceDateはdatetime型に変換しましたが、こちらも対象となっていて、first(期間が最も古い値)、last(期間が最も新しい値)が出力されています。
datetime型のデータ期間、日数の把握(”max()”, “min()”)
datetime型のデータの期間の把握は、to_datetimeでdatetime型に変換した上で、さきほど紹介した”describe(exclude=’number’)”のfirst, lastの項目で確認することができます。他にも、”max()”や”min()”を使って出力することも可能です。
format(df_ecomerce.InvoiceDate.min())# 出力
'2010-12-01 08:26:00'format(df_ecomerce.InvoiceDate.max())# 出力
'2011-12-09 12:50:00'また、minとmaxの差分を計算することも出来るので、その期間が何日あるのかも出力することが出来ます。
df_ecomerce["InvoiceDate"].max() - df_ecomerce["InvoiceDate"].min()# 出力
Timedelta('373 days 04:24:00')欠損値を調べる(”isnull().sum()”)
先程紹介したinfo()を用いることで各カラムに欠損値がどれくらいあるかを知ることが出来ましたが、他にもisnull().sum()を用いて欠損値を調べる方法もあります。この方法を用いると、欠損値の数だけでなく、全レコードの中での割合などを計算することが出来ます。
df_ecomerce.isnull().sum()# 出力
InvoiceNo 0
StockCode 0
Description 1454
Quantity 0
InvoiceDate 0
UnitPrice 0
CustomerID 135080
Country 0
dtype: int64欠損値の割合は以下のように算出出来ます。
df_ecomerce.isnull().sum() / df_ecomerce.shape[0] * 100# 出力
InvoiceNo 0.000000
StockCode 0.000000
Description 0.268311
Quantity 0.000000
InvoiceDate 0.000000
UnitPrice 0.000000
CustomerID 24.926694
Country 0.000000
dtype: float64欠損値件数、割合をまとめて算出する(おまけコード)
欠損値件数、割合をまとめて算出するコードです。
def calc_missing_rate(df, v):
total = df[v].isnull().sum()
percent = round(total / len(df[v])*100, 2)
return pd.DataFrame([[total, percent]], columns=["total", "ratio[%]"], index=[v])df_nans = pd.DataFrame(columns=["total", "ratio[%]"])
for i, col in enumerate(df_ecomerce.columns):
df_nans = pd.concat([df_nans, calc_missing_rate(df_ecomerce, col)])
display(df_nans)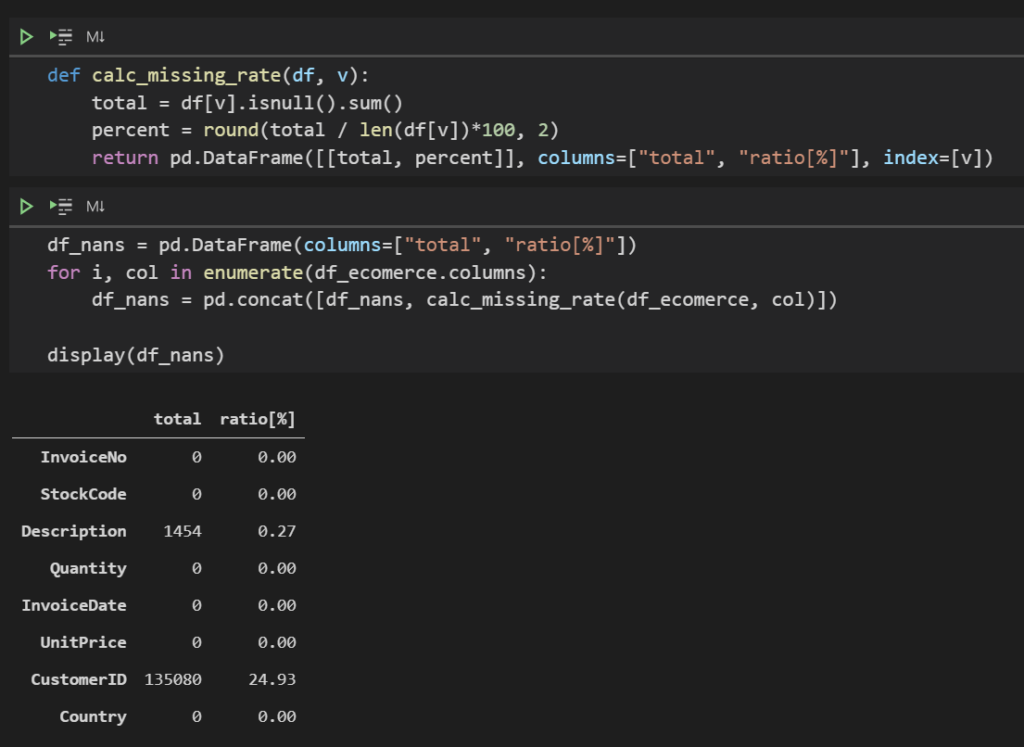
例えば、全レコードに占める欠損値が10%を超えるレコードを表示する場合は以下のように書きます。
df_nans[df_nans["ratio[%]"]>10]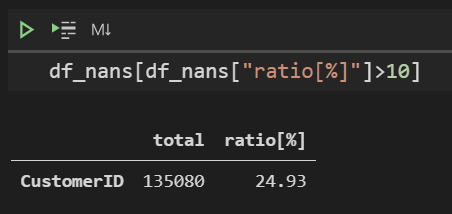
値の出現頻度を算出する(”value_counts()”)
あるカラムがどういう構成をしているかを、”.value_counts()”を使った値の出現頻度で見てみます。
例えば、”Country”の値がそれぞれ何件あるかを見てみます。
df_ecomerce["Country"].value_counts()# 出力
United Kingdom 495478
Germany 9495
France 8557
EIRE 8196
Spain 2533
Netherlands 2371
Belgium 2069
Switzerland 2002
Portugal 1519
Australia 1259
Norway 1086
Italy 803
Channel Islands 758
Finland 695
Cyprus 622
Sweden 462
Unspecified 446
Austria 401
Denmark 389
Japan 358
Poland 341
Israel 297
USA 291
Hong Kong 288
Singapore 229
Iceland 182
Canada 151
Greece 146
Malta 127
United Arab Emirates 68
European Community 61
RSA 58
Lebanon 45
Lithuania 35
Brazil 32
Czech Republic 30
Bahrain 19
Saudi Arabia 10
Name: Country, dtype: int64このように、指定したカラムの各値がそれぞれ何件あるのかが出力されました。ほとんどがイギリス、次いでドイツ、フランス、…となっているようです。
ちなみに、デフォルトでは欠損値が含まれていてもカウントされないです。欠損値も含めてカウントしたい場合は、”.value_counts(dropna=False)”というようにdropna引数にFalseを指定します。
value_countsで各値の件数および割合をまとめて集計する(おまけコード)
value_countsで各値の件数と、そのカラムの中でどれくらいの割合で出現しているかをまとめて算出するコードです。
for col_name, cnt in df_ecomerce["Country"].value_counts().iteritems():
cnt = "{:,}".format(cnt)
print("{}\t{} ({}%)".format(col_name, cnt, ratios[col_name]))# 出力
United Kingdom 495,478 (91.43%)
Germany 9,495 (1.75%)
France 8,557 (1.58%)
EIRE 8,196 (1.51%)
Spain 2,533 (0.47%)
Netherlands 2,371 (0.44%)
Belgium 2,069 (0.38%)
Switzerland 2,002 (0.37%)
Portugal 1,519 (0.28%)
Australia 1,259 (0.23%)
Norway 1,086 (0.2%)
Italy 803 (0.15%)
Channel Islands 758 (0.14%)
Finland 695 (0.13%)
Cyprus 622 (0.11%)
Sweden 462 (0.09%)
Unspecified 446 (0.08%)
Austria 401 (0.07%)
Denmark 389 (0.07%)
Japan 358 (0.07%)
Poland 341 (0.06%)
Israel 297 (0.05%)
USA 291 (0.05%)
Hong Kong 288 (0.05%)
Singapore 229 (0.04%)
Iceland 182 (0.03%)
Canada 151 (0.03%)
Greece 146 (0.03%)
Malta 127 (0.02%)
United Arab Emirates 68 (0.01%)
European Community 61 (0.01%)
RSA 58 (0.01%)
Lebanon 45 (0.01%)
Lithuania 35 (0.01%)
Brazil 32 (0.01%)
Czech Republic 30 (0.01%)
Bahrain 19 (0.0%)
Saudi Arabia 10 (0.0%)91%がイギリス、ドイツが1.75%、フランスが1.58%、…であるということが分かります。
数値のカラムにvalue_countsを適用するとどうなるか?
value_countsはカテゴリカルなカラムだけでなく、数値のカラムに対しても適用できます。ただし数値のカラムは値の分布が広い事が多いので、あまり有益な結果が得られない可能性があります。(数値のカラムの傾向を知るなら、ヒストグラムを描いたほうが良い事が多いです)
df_ecomerce["UnitPrice"].value_counts()# 出力
1.25 50496
1.65 38181
0.85 28497
2.95 27768
0.42 24533
...
4.48 1
87.40 1
545.25 1
0.48 1
221.16 1
Name: UnitPrice, Length: 1630, dtype: int64まとめ
今回はpandasを用いたテーブルデータの概要(サマリー)を把握する流れをまとめました。今回紹介した内容は、探索的データ分析(Exploratory Data Analysis: EDA)と呼ばれるデータに対する理解を深めるフェーズで多用される手法の一部になります。他にも、matplotlib (+ seaborn)を用いて視覚的にデータを把握する方法も組み合わせたほうが、より良いデータの素性把握につながることがあります。その辺りは次回以降にまとめたいと思います。
2022/01/10 追記:
pandas-profilingというテーブルデータの概要をサクッといい感じに可視化してくれる便利なツールの使い方を書きました。こちらも良ければご覧下さい。

