こんにちは。カルークです。
今日は、pandasのapply関数を使ったdataframeの操作について、いくつかの方法をまとめます。
実行環境
まずは実行環境についてですが、pandas 1.2.3を利用します。また、本コードはvs codeを用いたjupyter notebook上で実行しております。
import pandas as pd
pd.__version__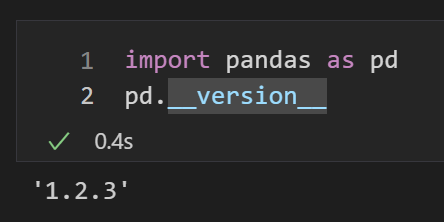
サンプルのデータフレームを作成
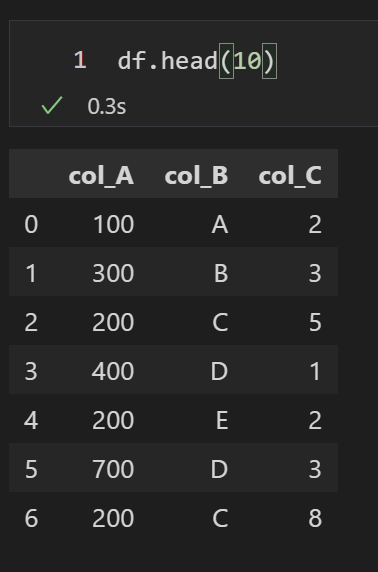
今回題材にするデータフレームを作成します。ちなみに、値に意味はありません。
df = pd.DataFrame({
"col_A": [100, 300, 200, 400, 200, 700, 200],
"col_B": ["A", "B", "C", "D", "E", "D", "C"],
"col_C": [2, 3, 5, 1, 2, 3, 8]
})
apply関数の利用例1:レコード単位で外部の関数に渡し、何らかの操作をする
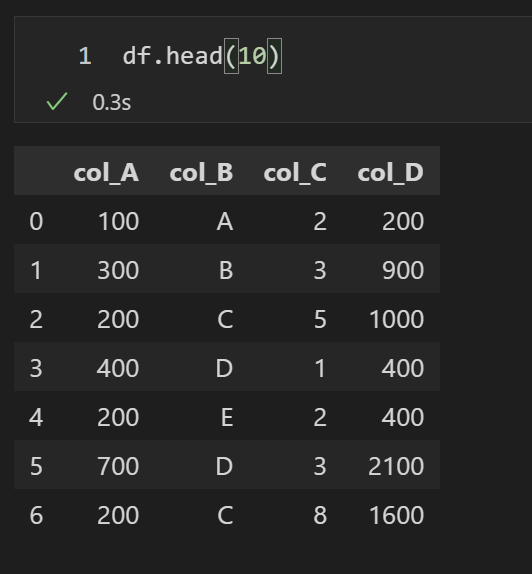
この方法では、とりあえずレコード単位で他に定義した関数(例ではfunc1)に値を渡し、関数側で何かの操作をします。データフレーム内の2個以上のカラムの値に対して何か操作を行いたい場合に有用です。
処理の内容としては、col_Aとcol_Cの掛け算を計算し、col_Dという列を元のデータフレームに追加するといった物です。
# 受け取ったレコードに対して、やりたい操作を記述する
def func1(row):
return row["col_A"] * row["col_C"]
# dfをレコード単位でfunc1に渡して何らかの操作をしてもらう。戻り値は新たに作成する"col_D"に保存する。
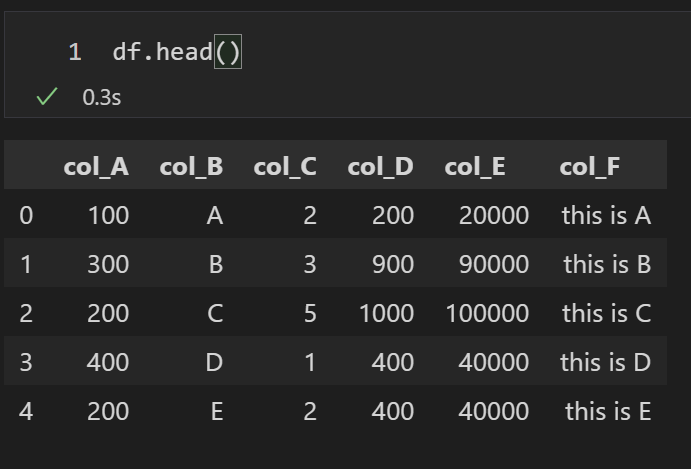
df["col_D"] = df.apply(func1, axis=1)実行後のdf.head()を見ると、col_Dにはcol_Aとcol_Cの掛け算の結果が入っているのが確認できます。
apply関数の利用例2:dataframe内の特定カラムに対し、何らかの操作をする
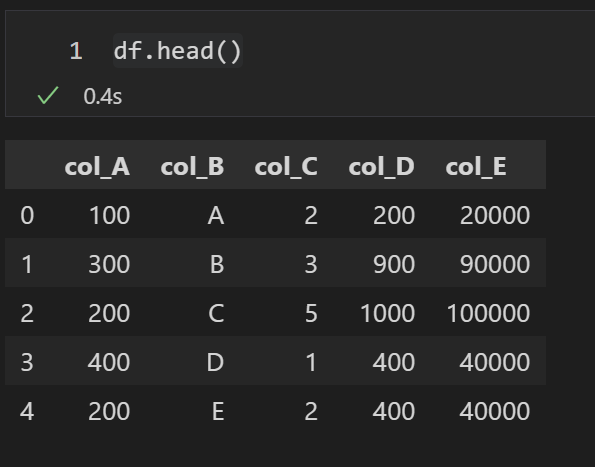
続いてはdataframe内の特定カラムに対して、外部の関数に定義したメソッドを使い何らかの操作をしたい場合の例です。
ここでは、col_Dに対し、100を乗じた値を計算し、それを新たなcol_Eとして作成するという事を行います。
# 受け取った値に対して、やりたい操作を記述する
def func2(x):
return x * 100
# dfの"col_D"の値をfunc2に渡して何らかの操作をしてもらう。戻り値は新たに作成する"col_E"に保存する。
df["col_E"] = df["col_D"].apply(func2)結果を見ると、col_Eにはcol_Dに対してfunc2を適用した結果が入っているのが確認できます。
文字列に対する操作の例
ここまでは、数値に対して外部の関数を使って何らかの操作を行っていましたが、文字列に対しても同様に出来ます。
例えば、col_Bに対して、func_3を使って文字列操作を行い、結果をcol_Fに入れてみます。
def func3(x):
return "this is " + str(x)
df["col_F"] = df["col_B"].apply(func3)結果を見てみると、col_Fにはcol_Bに対してfunc3で定義された操作(冒頭に”this is”を付与する)結果が保存されているのが確認できます。
apply関数の利用例3:lambda関数を使う方法
apply関数の利用例2で紹介した方法ですが、lambda関数を使うことで、より綺麗に記述することができます。
操作したいロジック(func2は受け取った値に100を乗ずる、func3は受け取った値の冒頭に”this is”を付与する)がシンプルな場合は、lambdaを使って実装したほうがコードの可読性が上がるのでおすすめです。
func3の例をlambdaで実現する場合
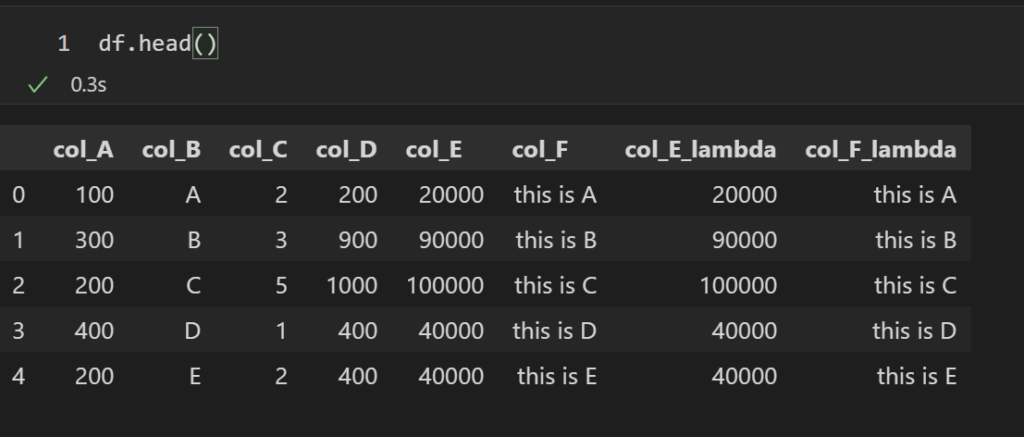
df["col_E_lambda"] = df["col_D"].apply(lambda x: x*100)func4の例をlanbdaで実現する場合
df["col_F_lambda"] = df["col_B"].apply(lambda x: "this is " + str(x))結果を見てみると、col_E_lambda, col_F_lamdaには、lambdaを使わない方法と同じ値が入っているのが確認できます。
おまけ:apply関数の進捗状況を確認する
レコード数が少ないデータフレームに対するapply関数の適用は、一瞬で実行が出来て実行時間はあまり気にならないかもしれません。しかし、レコード数が数万、数十万あるような巨大なデータフレームに対してapply関数を適用する場合には、いつ実行が終わるのかなって気になることがあります。
そんなときにはprogress_applyというメソッドを使うことで進捗状況を確認することが出来ます。
tqdmのインポート
progress_applyを利用するには、tqdmをインポートする必要があります。
また、tqdmのインポート後にtqdm.pandas()というおまじないコードを実行しておきます。(一度実行しておけば大丈夫です)
from tqdm import tqdm
tqdm.pandas()そして、applyメソッドの名前をprogress_applyとして再び実行します。ここでは例として、col_E_lambdaを作成したコードを再利用しています。
df["col_E_lambda"] = df["col_D"].progress_apply(lambda x: x*100)すると、以下のように進捗状況のプログレスバーが表示されるようになります。(今回は7件しかないので、一瞬で100%に達します)

まとめ
今回は、pandasのapply関数を使ったdataframeの操作について、いくつかの方法をまとめました。
