こんにちは。カルークです。
今日はscikit-learnと呼ばれる機械学習用のライブラリを使って、回帰問題を解いてみたいと思います。データは、ライブラリ内に付属するサンプル用のデータセットを用います。
scikit-learnとは
scikit-learnは、Python上で実行できる機械学習用のライブラリです。オープンソースなので誰でも無料で利用することが可能です。公式ページはコチラです。
– Simple and efficient tools for predictive data analysis
– Accessible to everybody, and reusable in various contexts
– Built on NumPy, SciPy, and matplotlib
– Open source, commercially usable – BSD license
https://scikit-learn.org/stable/
公式ページからの抜粋ですが、以下の特徴があります。
- データ予測分析のための、シンプルで効率的に利用できるツール
- 誰でも利用できて、様々なシーンで再利用も可能
- NumPy、SciPyとmatplotlibで作られれいる
- オープンソースで商用利用も可能(BSDライセンス)
出来ることとして、分類や回帰問題を解く、クラスタリングを行う、次元削減を行う、モデル自動選択、前処理などがあるようです。
自分自身、仕事で何度か簡単な用途で使ったことはありますが、様々な機械学習アルゴリズムが用意されていて、しかも数行のコードを書くだけでモデルの訓練から検証、ハイパーパラメーターチューニングまでやってくれるのは感動モノでした。
環境
まずは環境構築です。以下の環境で試しています。
- OS: Windows 10 (64 bit)
- Python環境: Anaconda、Python 3.6
- エディター: Jupyter Notebook
必要なパッケージをインストール
Anacondaプロンプトを起動し、仮想環境に入ってから以下のコマンドでパッケージをインストールします。(Anaconda以外の方は、condaをpipに置き換えて実行)
conda install scikit-learn仮想環境の作り方については、以前書いた以下の記事を参考にして作成ができます。
scikit-learnで回帰問題を解いてみる
それでは、jupyter notebook上でscikit-learnを使って回帰の問題を解いてみます。
データセットの準備、前処理
データセットはscikit-learnのライブラリ内に付随するボストンの家賃に関するデータを用います。
まずは、パッケージをインポートします。
from sklearn.datasets import load_boston続いて、データを読み込んでboston_dataという変数に格納します。
boston_data = load_boston()boston_dataを表示すると、辞書型でデータが格納されているのが確認できます。
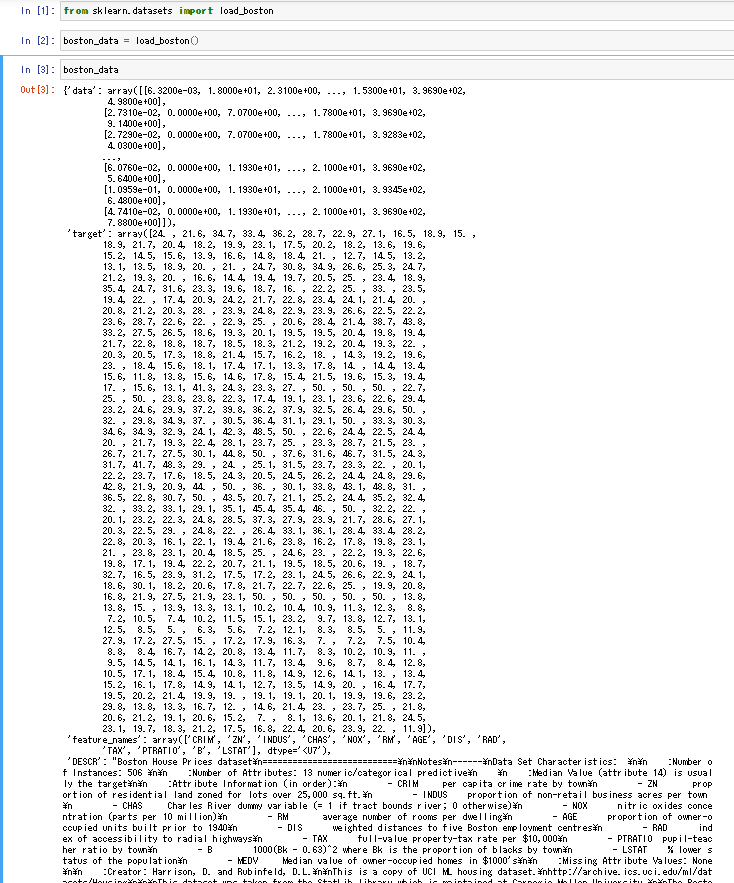
boston_dataの中に”data”という物件情報が入っていて、”target”の中に家賃情報が入っています。それぞれが、入力変数(説明変数)と出力変数(目的変数)となります。このデータを用いて、入力変数から出力変数を回帰で予測することを行います。
続いて、入出力の切り分けを行い、入力変数(x)と出力変数(t)にデータを格納するようにします。
x = boston['data']
t = boston['target']データのサイズを確認しておきます。
x.shape(506, 13)と出ているはずです。これは、506個のサンプル数で、カラムが13個あるテーブルデータのイメージです。
ここまでで、データの前処理が完了しました。
回帰の実行
続いて回帰をやってみます。ここでは、重回帰と呼ばれる線形の回帰手法を選択します。
重回帰について補足
重回帰は複数の説明変数から目的変数を直線のモデルで予測する推論の方法となります。イメージとしては、中学生の頃に習ったy=axの直線の方程式があると思いますが(切片bは簡単のため省略)、説明変数であるxから「良い感じ」に目的変数yを予測する線形のモデルとなります。その「良い感じ」を実現するために、適切なパラメータaをデータから学習するのが今からやりたい事です。(実際は重回帰なので説明変数はx1, x2, x3,…のように複数になります。y=a1x1 + a2x2 + …のような感じです。このa1, a2,…の最適な値を学習から求めます。)
「良い感じ」を実現するためにはどうすれば良いでしょうか?それは「評価関数」というものを定義し、「評価関数」が最小となるようなパラメータを決めてあげることをします。具体的には、モデルに対して入力変数を入れてみて、出てきた結果(予測値)と本当の値(教師データ)を比較し(それを表現するのが評価関数)、その差分が小さくなるようにパラメータを調整してあげる事をします。
まずはパッケージのインポートから行います。
from sklearn.linear_model import LinearRegression続いて、クラスをインスタンス化して”model”という変数に入れておきます。
model = LinearRegression()そしてモデルの学習を行います。つまりここで上記で説明したパラメータa1, a2, a3…が最適化されます。
model.fit(x, t)たったこの1行で学習が完了してしまいます。scikit-learn凄いです。
モデルは作っただけでは終わりにせず、適切に予測が出来るかを評価してみます。
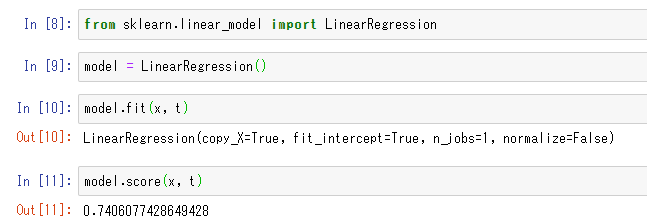
回帰でのモデルの評価は決定係数(0-1の範囲でモデルの良さを判定。1が良い、0がダメモデル)が使われることが多いですが、以下の1行で決定係数を算出してくれます。
model.score(x, t)以下のように、0.74程度になっていれば正しく実行ができています。
ここまでで、scikit-learnを使った回帰の基本的な使い方についてのまとめでした。
実際は訓練データと検証データに分ける必要があるので注意
実際はデータを訓練データと検証データに分割し、訓練データのみで学習して、検証データでモデルの予測精度を検証するということをやるのが一般的です。そうしないと、学習したモデルが未知のデータに対しても正しく予測できるのかが分からないからです。もしかしたら、訓練データでは正しく予測ができるのに、未知のデータが来た途端に予測が外れるかもしれません。そのような事を、「過学習(オーバーフィッティング)している」と言います。
過学習していないことを確認するために、訓練データの評価だけでなく、必ず検証データの評価も同時に行っておく必要があります。訓練データで評価が高いことを確認しつつ、検証データでも評価が高いことを確認しましょう。
訓練データと検証データにデータを分割する
それでは、訓練データと検証データにデータを分割して、それぞれで評価をしてみます。
まずは、データを分割するためのパッケージをインポートします。
from sklearn.model_selection import train_test_split続いて、データを訓練と検証に分けてみます。それぞれ説明変数(x)と目的変数(t)があるので、元のテーブル(506行13列)を4分割するイメージです。
ここでは、訓練:検証を6:4の割合で分割してみます。
x_train, x_test, t_train, t_test = train_test_split(x, t, test_size=0.4, random_state=0)x_trainは、訓練データの説明変数、x_testは検証データの説明変数、t_trainは訓練データの目的変数(教師)、t_testは検証データの目的変数(教師)となります。順序がややこしいので、注意が必要です。train_test_splitのrandom_stateは乱数の固定のために書いています。乱数を固定しないと実行のたびに結果が微妙に変わるためです(パラメータの初期値を乱数で決めている事に起因)。test_sizeは検証データの割合を表します。今回は全体の4割を検証データとするので、0.4となっています。
続いて、先程同様にモデルのインスタンス化を行い、fit関数で訓練データを使って学習をさせます。
model = LinearRegression()
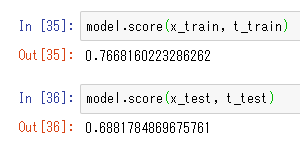
model.fit(x_train, t_train)そして評価をします。先程と同じくmodelの中に入っているscore関数を用います。
model.score(x_train, t_train)model.score(x_test, t_test)結果は以下のようになっていると思います。訓練データに対する評価スコアは0.77に対し、検証データに対する評価スコアは0.69です。若干は訓練データにフィット(過学習)しがちですが、そこまで大きく乖離はしていないのと、スコア自体も7割くらいなので悪くはないといった結果になっています。
予測をしてみる
学習済モデルを使って、何か入力を与えてみた時の出力(家賃)を予測してみます。
本来は未知の値を入力としたい所ですが、簡易的に結果を確認するために訓練データの中の任意の値を使って予測値を出してみたいと思います。
x_ = x[0] # boston_dataのxの最初のデータ中身はこのようになっています。

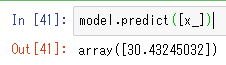
モデルにx_を入力し予測値を得ます。
model.predict([x_])たったこれだけで予測値が以下のように得られます。
まとめ
今回は機械学習用ライブラリであるscikit-learnを用いて、回帰の問題を解いてみました。データの取得から始まり、訓練と検証データに分割する方法、評価の方法について書きました。scikit-learnを用いると非常に簡単にこれだけの事ができるというのが実感できたかと思います。